들어가며
이번 장은 ⌜빅데이터를 지탱하는 기술⌟ 리뷰의 마지막 장으로, 지금까지 배운 내용들을 기반으로 실제 실습을 진행해보도록 하겠습니다.
1. Spark를 통한 대화식 애드 혹 분석
스키마리스 데이터 수집
먼저, 실제 데이터를 수집하는 과정이 필요합니다. 책에서 사용한 twitter streaming api는 무료계정으로 사용하는 것이 불가능하여, reddit 의 hot api 로 테스트 하였습니다. 코드 자체는 거의 동일합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| # reddit api docs : https://www.reddit.com/dev/api
import datetime
import json
import requests
import tqdm
import configparser
import pymongo
# config/SystemConfig.ini
config = configparser.ConfigParser()
config.read('../config/SystemConfig.ini')
# api configs
CLIENT_ID = config['REDDIT_CONFIG']['reddit.client_id']
CLIENT_SECRET = config['REDDIT_CONFIG']['reddit.client_secret']
USERNAME = config['REDDIT_CONFIG']['reddit.username']
PASSWORD = config['REDDIT_CONFIG']['reddit.password']
AUTH_TOKEN = config['REDDIT_CONFIG']['reddit.auth_token']
# print("client_id = {}, client_secret = {}, username = {}, password = {}, auth_token = {}".format(CLIENT_ID,CLIENT_SECRET,USERNAME,PASSWORD,AUTH_TOKEN))
def bearer_oauth(r):
"""
Method required by bearer token authentication.
"""
r.headers["Authorization"] = f"Bearer {AUTH_TOKEN}"
return r
base_url = 'https://oauth.reddit.com/hot'
response = requests.get(base_url, auth=bearer_oauth, stream=True)
print(response)
# save in mongo
mongo = pymongo.MongoClient()
def reddit(*args, **kwargs):
for reddit in mongo.reddit.sample.find(*args, **kwargs):
yield {
'timestamp' : reddit['_timestamp'],
'title' : reddit['title']
}
df = pd.DataFrame(reddit({'score':{'$gt':0}}, limit=50))
# df
|
prerequisites
- MongoDB version 4.0 or later
- Spark version 3.1 through 3.2.4
- Java 8 or later
1
2
3
4
5
6
7
8
9
10
11
12
| # pips
pip3 install pyspark==3.1.2
pip3 install install ipywidgets ipykernel metakernel py4j pandas
pip3 install "IPython<8.0.0"
pip3 install pyspark_kernel
# jars
146K Apr 2 22:02 mongodb-driver-sync-4.8.2.jar
1.5M Apr 2 22:03 mongodb-driver-core-4.8.2.jar
496K Apr 2 22:03 bson-4.8.2.jar
13K Apr 2 22:03 bson-record-codec-4.8.2.jar
173K Apr 3 08:12 mongo-spark-connector_2.12-10.2.2.jar
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]") \
.appName("reddit") \
.config("spark.jars", \
"/home/seungyeup/spark-3.5.1-bin-hadoop3/jars/mongodb-driver-sync-5.1.2.jar") \
.config("spark.jars.packages", \
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1,org.mongodb.spark:mongo-spark-connector_2.12:3.0.1") \
.getOrCreate()
# print(spark)
df = spark.read.format("com.mongodb.spark.sql.DefaultSource")\
.option("uri", "mongodb://10.0.0.1:27017/reddit.sample2")\
.load()
df.createOrReplaceTempView('reddits')
query = '''
select * from reddits
'''
spark.sql(query).show(3)
# query = '''
# select subreddit, count(*)
# from reddit
# where score >= 0
# group by 1
# order by 2 desc
# '''
# spark.sql(query).show(5)
|
reddit sample data
reddit sample data2
데이터를 수집한 결과는 위와 같습니다. 수집한 데이터를 pyspark에서 조회하면 다음과 같습니다.
쿼리 수행속도 비교에 적절한 데이터 용량은 물론 아니지만, MongoDB의 경우 열 지향 스토리지와 같이 칼럼 단위 읽기에 최적화 된 DB는 아닙니다. 따라서 고속 집계에는 적합하지 않으므로 최적화를 위해서 한 차례 데이터를 추가로 추출해야 합니다.
spark 를 통한 데이터의 가공
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| from pyspark.sql import SparkSession
spark = SparkSession \
.builder.master("myApp") \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.config("spark.mongodb.read.connection.uri", "mongodb://127.0.0.1:27017/reddit.sample") \
.config("spark.mongodb.write.connection.uri", "mongodb://127.0.0.1:27017/reddit.sample") \
.config("spark.driver.bindAddress", "127.0.0.1") \
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.12:10.2.0') \
.getOrCreate()
df = spark.read.format('mongodb')\
.option("spark.mongodb.read.database", "reddit") \
.option("spark.mongodb.read.collection", "sample") \
.load()
df.createOrReplaceTempView('reddit')
from pyspark.sql import Row
def text_split(row):
for word in row.title.split():
yield Row(time=row.timeline, word=word)
query = '''
select _timestamp timeline, title
from reddit
'''
titles_from_reddit = spark.sql(query)
# titles_from_reddit.show(5)
# titles_from_reddit.rdd.take(1)
titles_from_reddit.rdd.flatMap(text_split).take(2)
titles_from_reddit.rdd.flatMap(text_split).toDF().show(2)
|
그 다음은 flatMap() 내에서 텍스트 분해를 위한 함수를 실행하고, 다시 데이터 프레임을 만듭니다.
1
2
3
4
5
6
7
8
9
10
|
words = titles_from_reddit.rdd.flatMap(text_split).toDF()
words.createOrReplaceTempView('words')
query = '''
select word, count(*)
from words group by 1 order by 2 desc;
'''
spark.sql(query).show(3)
|
분해된 데이터는 어느정도 정리된 상태에서 물리적인 테이블로 보관하도록 합니다.
1
2
3
4
5
6
7
8
9
| words.write.saveAsTable('reddit_sample_words')
import subprocess
result = subprocess.getoutput('ls -R spark-warehouse')
result
# 결과
'reddit_sample_words\n\nspark-warehouse/reddit_sample_words:\n_SUCCESS\npart-00000-8765ec86-3309-4854-8645-8f93a880f744-c000.snappy.parquet'
|
데이터 집계에서 더 나아가, 시각화에 적합한 데이터 마트를 만듭니다. 여기서는 선택지가 몇가지 있습니다.
- Spark에 ODBC/JDBC로 접속하기
- MPP 데이터베이스에 비정규화 테이블 만들기
- 데이터를 작게 집약하여 CSV 파일에 출력하기
1
2
3
4
5
6
7
8
| spark.table('reddit_sample_words').count()
query = '''
select substr(time, 1, 13)time, word, count(*) count
from reddit_sample_words group by 1, 2
'''
spark.sql(query).count()
|
카디널리티 삭감
카디널리티가 높은 칼럼은 데이터 제약의 방해가 됩니다. 따라서 사용하는 빈도가 낮은 데이터는 따로 분리하여 보관할 필요가 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# query = '''
# select t.count, count(*) words
# from (
# select word, count(*) count from reddit_sample_words group by 1
# ) t
# group by 1 order by 1
# '''
query = '''
select word, count,
if(count > 1000, word, concat('count=',count)) category
from (
select word, count(*) count from reddit_sample_words group by 1
)t
'''
spark.sql(query).show(10)
spark.sql(query).createOrReplaceTempView('word_category')
|
여기까지 왔다면 좀 더 집약이 가능하다. 1시간마다 카테고리별로 그룹화하여 집계하여보자.
1
2
3
4
5
6
7
8
| query='''
select substr(a.time, 1, 13) time, b.category, count(*) count
from reddit_sample_words a
left join word_category b on a.word = b.word
group by 1,2
'''
spark.sql(query).count()
|
결과적으로 집계된 결과를 CSV 파일로 작성하도록 합니다. Spark에서 집계는 두가지 방법이 있습니다.
- 표준 spark-csv 라이브러리 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
spark.sql(query)
.coalesce(1) # 출력 파일은 하나로 한다.
.write.format('com.databricks.spark.csv') # csv 형식 사용한다.
.option('header', 'true') # 헤더 사용
.save('csv_output') # 출력 디렉터리
# spark.sql(query).coalesce(1).write.format('com.databricks.spark.csv').option('header', 'true').save('csv_output')
import subprocess
result = subprocess.getoutput('ls csv_output')
# '_SUCCESS\npart-00000-a1db7b63-6cdex-4aee-a611-34b2bcf37440-c000.csv'
|
- pandas df 사용
1
2
3
4
5
|
import pandas
result = spark.sql(query).toPandas()
|
2. Hive와 Presto를 통한 재구축
1
2
3
|
!pip install -r ../requirements.txt
|
1
2
3
4
5
6
7
8
|
import datetime
import json
import requests
import tqdm
import configparser
import pymongo
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# config/SystemConfig.ini
config = configparser.ConfigParser()
config.read('../config/SystemConfig.ini')
# api configs
CLIENT_ID = config['REDDIT_CONFIG']['reddit.client_id']
CLIENT_SECRET = config['REDDIT_CONFIG']['reddit.client_secret']
USERNAME = config['REDDIT_CONFIG']['reddit.username']
PASSWORD = config['REDDIT_CONFIG']['reddit.password']
AUTH_TOKEN = config['REDDIT_CONFIG']['reddit.auth_token']
|
1
2
3
|
print("client_id = {}, client_secret = {}, username = {}, password = {}, auth_token = {}".format(CLIENT_ID,CLIENT_SECRET,USERNAME,PASSWORD,AUTH_TOKEN))
|
1
2
3
|
# 토큰 만료되었다면 재발급 받아야 함!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def bearer_oauth(r):
"""
Method required by bearer token authentication.
"""
r.headers["Authorization"] = f"Bearer {AUTH_TOKEN}"
return r
base_url = 'https://oauth.reddit.com/hot'
response = requests.get(base_url, auth=bearer_oauth, stream=True)
print(response)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# save in mongo
mongo = pymongo.MongoClient()
for line in response.iter_lines():
if line:
reddit = json.loads(line)
for child in tqdm.tqdm(reddit['data']['children'], unit='reddit', mininterval=10):
data = {
'_timestamp': datetime.datetime.utcnow().isoformat(),
"subreddit": child['data']['subreddit'],
"author_fullname": child['data']['author_fullname'],
"title": child['data']['title'],
"score": child['data']['score'],
"url": child['data']['url']
}
mongo.reddit.sample2.insert_one(data)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import pandas as pd
import pymongo
mongo = pymongo.MongoClient()
def reddit(*args, **kwargs):
for reddit in mongo.reddit.sample.find(*args, **kwargs):
yield {
'timestamp' : reddit['_timestamp'],
'title' : reddit['title']
}
df = pd.DataFrame(reddit({'score':{'$gt':0}}, limit=50))
df
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]") \
.appName("reddit") \
.config("spark.jars", \
"/home/seungyeup/spark-3.5.1-bin-hadoop3/jars/mongodb-driver-sync-5.1.2.jar") \
.config("spark.jars.packages", \
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1,org.mongodb.spark:mongo-spark-connector_2.12:3.0.1") \
.getOrCreate()
print(spark)
|
1
2
3
| df = spark.read.format("com.mongodb.spark.sql.DefaultSource")\
.option("uri", "mongodb://10.0.0.1:27017/reddit.sample2")\
.load()
|
1
2
3
4
5
6
7
8
9
|
df.createOrReplaceTempView('reddits')
query = '''
select * from reddits
'''
spark.sql(query).show(3)
|
1
2
3
4
5
6
7
8
9
10
11
|
query = '''
select _timestamp, title
from reddits where score >= 20
'''
spark.sql(query).show(3)
filtered_reddits = spark.sql(query)
|
1
2
3
4
5
6
7
|
from pyspark.sql import Row
def text_split(row):
for word in row.title.split():
yield Row(time=row._timestamp, word=word)
|
1
2
3
4
|
filtered_reddits.rdd.take(1)
# filtered_reddits.rdd.flatMap(text_split).take(2)
|
1
2
3
|
filtered_reddits.rdd.flatMap(text_split).take(2)
|
1
2
3
|
filtered_reddits.rdd.flatMap(text_split).toDF().show(3)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
words = filtered_reddits.rdd.flatMap(text_split).toDF()
words.createOrReplaceTempView('words')
query = '''
select word, count(*)
from words group by 1 order by 2 desc
'''
spark.sql(query).show(3)
for_hive_test = spark.sql(query).toPandas()
for_hive_test.head(2)
|
1
| words.write.saveAsTable('reddit_sample_words_2')
|
1
2
3
4
5
6
7
8
9
10
11
|
# Spark에ODBC/JDBC로접속하기
# • MPP데이터베이스에비정규화테이블만들기
# • 데 이 터 를 작 게 집 약 하 여 C S V 파 일 에 출력 하 기
# reddit_sample_words
spark.table('reddit_sample_words_2').count()
|
1
2
3
4
5
6
7
8
9
10
11
12
|
query = '''
select substr(time, 1, 13) time, word, count(*) count
from reddit_sample_words_2 group by 1, 2
'''
spark.sql(query).count()
|
1
2
3
4
5
6
7
8
9
10
11
12
|
query = '''
select t.count, count(*) words
from (
select word, count(*) count from reddit_sample_words_2 group by 1
) t
group by 1 order by 1
'''
spark.sql(query).show(3)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
query = '''
select word, count, if(count > 5, word, concat('count=',count)) category
from (
select word, count(*) count from reddit_sample_words_2 group by 1
) t
'''
# spark.sql(query).show()
spark.sql(query).createOrReplaceTempView('word_category')
|
1
2
3
4
5
6
7
8
9
10
11
12
|
query = '''
select substr(a.time, 1, 13) time, b.category, count(*) count
from reddit_sample_words_2 a
left join word_category b on a.word = b.word
group by 1, 2
'''
spark.sql(query).count()
|
1
2
3
4
5
6
|
# CSV 파일 작성
# 표준 spark-csv 사용
spark.sql(query).coalesce(1).write.format('com.databricks.spark.csv').option('header', 'true').save('csv_output_2')
|
1
2
3
|
!hdfs dfs -ls /user/seungyeup/
|
1
2
3
4
|
result = spark.sql(query).toPandas()
result.head(2)
|
1
2
3
4
5
6
|
import pandas as pd
result['time'] = pd.to_datetime(result['time'])
result.head(2)
|
1
2
3
|
result.to_csv('word_summary.csv', index=False, encoding='utf-8')
|
1
2
3
4
5
6
7
8
9
10
11
|
# 벌크형 데이터 전송 : Embulk
# 분산시스템 : hadoop
# 데이터 구조화 : hive
# 쿼리 엔진 : presto
# mongo (datasource)
# -> [embulk] -> json file
# -> [hive] -> ORC
# -> [presto] -> CSV
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# # Embulk 설치 (과거버전 -> 이렇게 하면 실패함)
# (2) Install Java 8
# EMbulk only operates with Java 8. -> 공홈(https://www.embulk.org/) 에 보면 11,17,21는 성공여부에 확실치 않음
# ```
# sudo apt install openjdk-8-jre-headless
# ```
# (3) Check Java version
# ```
# $ java -version
# openjdk version "1.8.0_352"
# OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~20.04-b08)
# OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
# ```
# (4) Install Embulk
# ```
# curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
# chmod +x ~/.embulk/bin/embulk
# echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
# source ~/.bashrc
# ```
# (5) Check embulk command
# ```
# which embulk
# ```
# # 플러그인 설치
# embulk gem install embulk-input-mongodb embulk-formatter-jsonl
# ==> 위 방법으로는 막혀서 더이상 동작하지 않음
# (https://github.com/embulk/embulk/issues/1496)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# # Embulk 설치 현재버전
# 1) wget https://github.com/embulk/embulk/releases/download/v0.11.4/embulk-0.11.4.jar
# 2) java -jar ~/.embulk/bin/embulk-0.11.4.jar -version
# 3) jruby .jar 설치
# cd ~/.embulk
# wget https://repo1.maven.org/maven2/org/jruby/jruby-complete/9.4.8.0/jruby-complete-9.4.8.0.jar
# vi ~/.embulk/embulk.properties
# -> jruby=file:///path/to/jruby-complete-9.x.y
# # 플러그인 설치
# java -jar ~/.embulk/bin/embulk-0.11.4.jar gem install embulk -v 0.11.4
# java -jar ~/.embulk/bin/embulk-0.11.4.jar gem install embulk-input-mongodb
# java -jar ~/.embulk/bin/embulk-0.11.4.jar gem install embulk-formatter-jsonl
# java -jar ~/.embulk/bin/embulk-0.11.4.jar gem install msgpack
# => 새로 공홈에서 안내하는 방법.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# #! /bin/bash
# START="$1"
# END="$2"
# cat > config.yml << EOF
# in:
# type: mongodb
# uri: mongodb://localhost:27017/reddit
# collection: sample
# query: '{"__timestamp": {\$gte: "${START}", \$lt: "${END}"}}'_
# projection: '{ "timestamp_ms": 1, "lang": 1, "text": 1}'
# out:
# type: file
# path_prefix: /tmp/reddit_sample__${START}/_
# file_ext: json.gz
# formatter:
# type: jsonl
# encoders:
# type: gzip
# EOF
# rm -rf /tmp/reddit_sample__${START}_
# mkdir /tmp/reddit_sample__${START}_
# embulk run config.yml
|
1
2
3
4
5
6
|
# EMBULK
# https://plugins.embulk.org/
# https://bcho.tistory.com/1126
# https://www.embulk.org/
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# HIVE 셋업
# https://dlcdn.apache.org/hive/hive-4.0.0/apache-hive-4.0.0-bin.tar.gz
# $tar -xzvf hive-x.y.z.tar.gz
# $ cd hive-x.y.z
# $ export HIVE_HOME=
# $ export PATH=$HIVE_HOME/bin:$PATH
|
1
2
3
4
5
6
7
|
# HIVE 메타스토어 기동 -> Hive 3.1.3 버전에서는 Metastore를 별도로 기동하지 않아도 됨
# /user/hive/warehouse 에 hive 테이블이 만들어지므로 미리 생성
# ~/batch 디렉토리 생성하고, 그 안에서 아래 명령어 수행
# schematool -initSchema -dbType derby
# hive --service metastore ->
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# # hive 데이터 구조화 쿼리
# # json 파일 로드 라이브러리
# ADD JAR /home/seungyeup/hive/hcatalog/share/hcatalog/hive-hcatalog-core-4.0.0.jar
# # json 파일을 읽기 위한 외부 테이블
# CREATE TEMPORARY EXTERNAL TABLE reddit_sample(
# record struct<timestamp_ms:string, lang:string, text:string>
# )
# ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
# STORED AS TEXTFILE LOCATION '/tmp/reddit_sample__${STRAT}/';_
# # 출력 테이블(파티션 분할, ORC 형식)
# CREATE TABLE IF NOT EXIST reddit_sample_words(
# time timestamp, word string
# )
# PARTITIONED BY (pt string) STORED AS ORC;
# # 날짜 지점으로 파티션 덮어쓰기
# INSERT OVERWRITE TABLE reddit_sample_words PARTITION (pt='${START}')
# SELECT from_unixtime(cast(record.timestamp_ms / 1000 as bigint)) time, word
# FROM reddit_sample
# LATERAL VIEW explode(split(record.text, '\\s+')) words as word
# WHERE record.lang = 'en' ORDER BY time
|
1
| # Hive는 java8에서 지원되므로 hadoop-env.sh 에서 JAVA_HOME을 8로 바꿔주었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
ADD JAR /home/seungyeup/hive/hcatalog/share/hcatalog/hive-hcatalog-core-3.1.3.jar;
CREATE EXTERNAL TABLE IF NOT EXISTS reddit_sample(
record struct<word:string>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE LOCATION '/tmp/reddit_sample__${START}/';_
CREATE TABLE IF NOT EXISTS reddit_sample_words(
word string
)
PARTITIONED BY(pt string) STORED AS ORC;
INSERT OVERWRITE TABLE reddit_sample_words PARTITION (pt='${START}')
SELECT record.word FROM reddit_sample;
INSERT OVERWRITE TABLE reddit_sample_words PARTITION (pt='1')
SELECT record.word FROM reddit_sample;
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# # HIVE 4.0.0 부터는 ADD JAR 동작하지 않음
# Hive 4.0.0에서는 ADD JAR 명령어가 더 이상 지원되지 않습니다. Hive 4.x 버전에서는 UDF(User-Defined Function)나 기타 JAR 파일을 추가하는 방식이 변경되었습니다.
# Hive 4.0.0부터는 HiveStrictManagedTables 기능이 기본적으로 활성화되어 있으며, 이로 인해 ADD JAR 명령어와 같은 일부 기능이 제한되거나 작동하지 않게 되었습니다. 대신, Hive 4.x에서는 아래와 같은 방법으로 JAR 파일을 등록하고 사용해야 합니다:
# Hive CLI 또는 Beeline에서 JVM 옵션 설정:
# HIVE_AUX_JARS_PATH 또는 hive.aux.jars.path 설정을 통해 JAR 파일을 Hive의 classpath에 추가할 수 있습니다.
# HiveServer2에서 설정:
# HiveServer2가 시작될 때, JAR 파일을 포함하도록 설정 파일을 수정해야 합니다. 예를 들어, hive-site.xml 파일에서 hive.aux.jars.path 속성을 사용하여 JAR 파일 경로를 지정할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
|
# 오류 발생
# Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
# Caused by: java.lang.NoSuchFieldException: parentOffset
# at java.base/java.lang.Class.getDeclaredField(Class.java:2411)
# at org.apache.hadoop.hive.ql.exec.SerializationUtilities$ArrayListSubListSerializer.<init>(SerializationUtilities.java:382)
# ... 20 more
|
1
2
3
4
5
6
7
8
9
|
# 결국 hive 4 + MR 로 진행함.
# hive-site 에 config 추가
# beeline 으로 hiveserver2에 연결 확인 후, 파라미터 전달해서 .hql 파일 실행
# 예시: $HIVE_HOME/bin/beeline -u jdbc:hive2://localhost:10000 -f load.hql --hivevar START=1
# 참조: https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
# 로그: tail -f /tmp/seungyeup/hive.log
|
1
2
3
4
5
6
7
8
9
| # 설치 : wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.288.1/presto-server-0.288.1.tar.gz
# https://prestodb.io/docs/current/installation/deployment.html
# config 파일 생성
# ./bin/launcher run (start는 백그라운드 실행)
# cli 다운로드
# wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.288.1/presto-cli-0.288.1-executable.jar
# ./presto --server localhost:8087
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # presto는 derby -> postresql로 넘어가거나
#I solved this by replaced the Derby with PostgreSQL
# MySQL 에서도 될 거 같다는..?
# https://github.com/nico-arianto/big-data-local/issues/1
# presto -> trino 로 넘어가야함
# https://github.com/prestodb/presto/issues/10735
# 일단 metastore db 를 mysql로 하고, 메타스토어 서버를 실행시킨 뒤, hiveserver2 실행시켜서 hql 파일로 데이터를 upload.
# 그 후 presto 실행시키고, cli로 접속해서 데이터 조회
|
1
2
3
4
5
6
7
|
# 하이브
# https://cwiki.apache.org/confluence/display/Hive/GettingStarted
# presto
# https://prestodb.io/docs/current/installation/deployment.html
|
정리하며
여기까지 ⌜빅데이터를 지탱하는 기술(BIG DATA WO SASAERU GIJUTSU)⌟ 을 읽고 정리하는 시간을 가졌습니다. 다시 읽어봐도 좋은 내용들이 참 많아 틈틈히 이곳 포스트에 돌아와 내용을 보충하고자 합니다. 👋
참고문헌

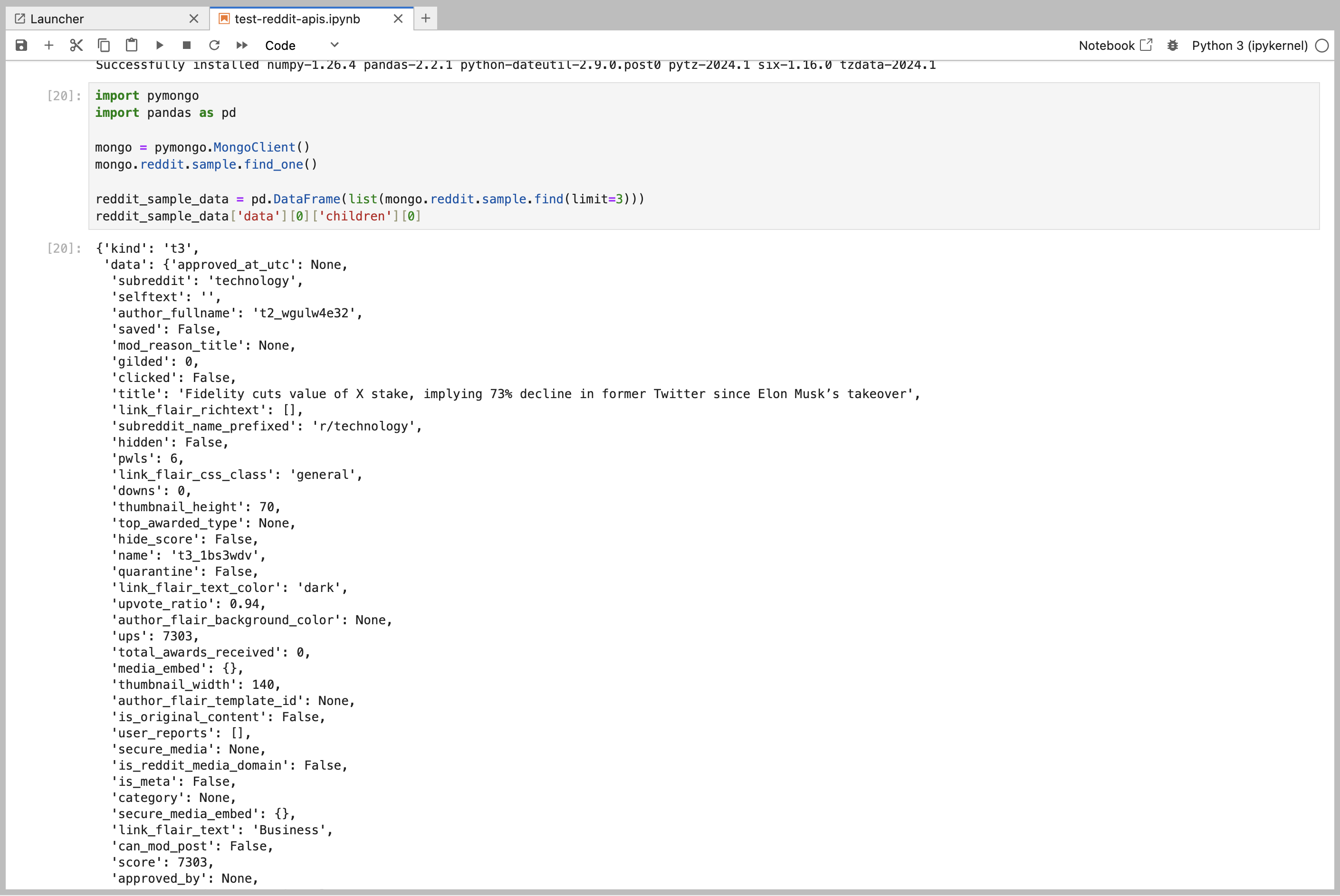 reddit sample data
reddit sample data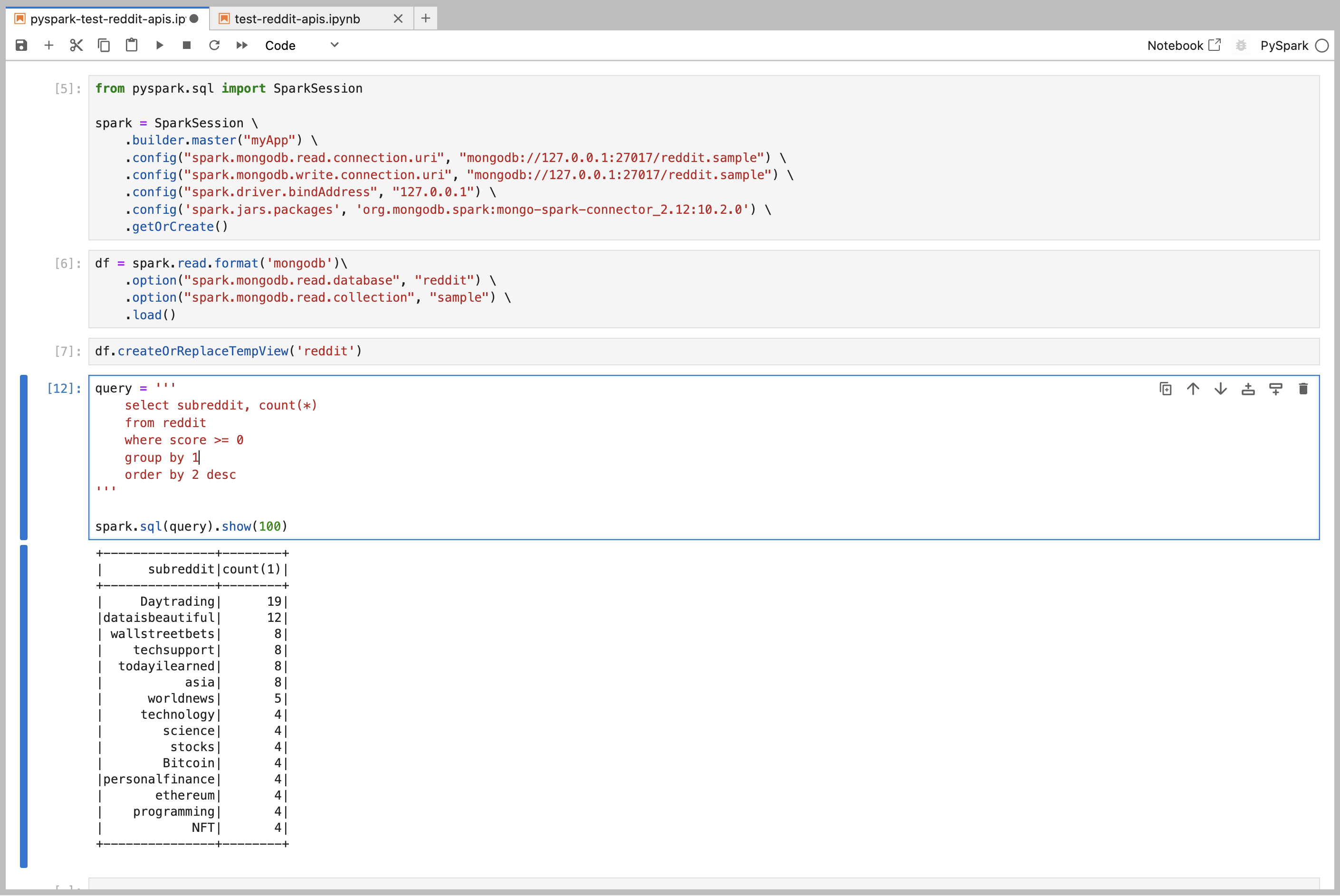 reddit sample data2
reddit sample data2