
들어가며
지난번 포스팅에서는 elasticsearch의 JVM-heap-memory가 증가한 원인에 대해 알아봤습니다. 이번 포스팅에서는 적절한 샤드 구성은 어떻게 할 수 있는지 간단하게 알아보도록 하겠습니다.
샤드(Shard)란 무엇인가
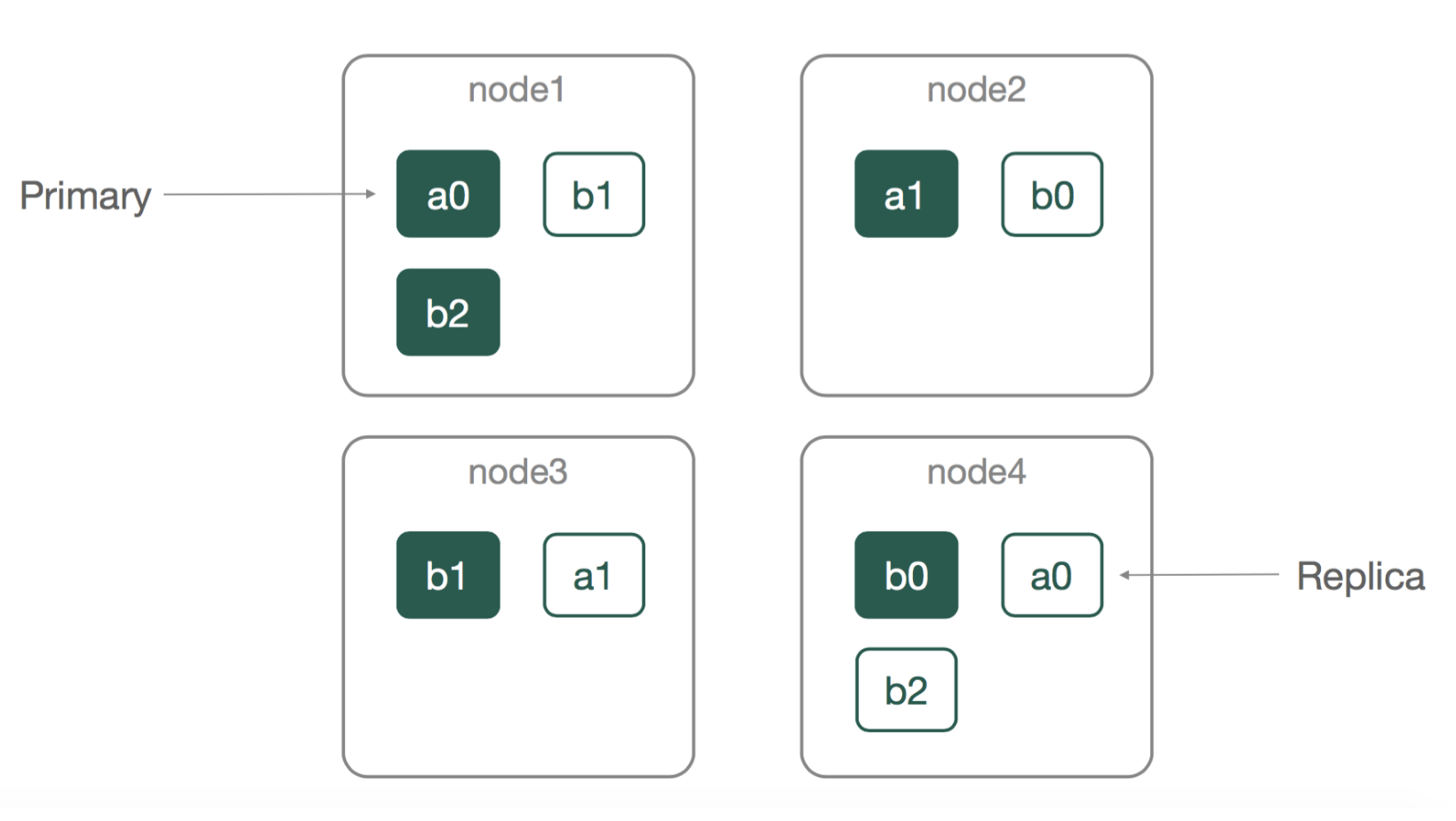 primary shard and replication shard elasticsearch 에서는 인덱스에 데이터를 저장하면서
primary shard and replication shard elasticsearch 에서는 인덱스에 데이터를 저장하면서 shard 라고 하는 소단위로 쪼개어 저장합니다. 원본 데이터를 쪼갠 조각들을 primary-shard 라 하고, 이 조각들에 대한 복제본은 replication-shard라 합니다. 원본데이터를 쪼갬(primary-shard)으로서 여러 노드에서 분산처리가 가능해짐과 동시에 검색과 색인 작업이 여러 샤드에서 동시에 일어날 수 있게 됩니다. 또한 이를 복제(replication-shard)하여 고가용성을 확보한 것입니다.
primary-shard가 유실되면 어떻게 될까요?
primary-shard가 유실되면 남아있던replication-shard가 승격되어primary-shard가 되고, elasticsearch는 자동으로 새로운 replication을 추가 생성합니다.
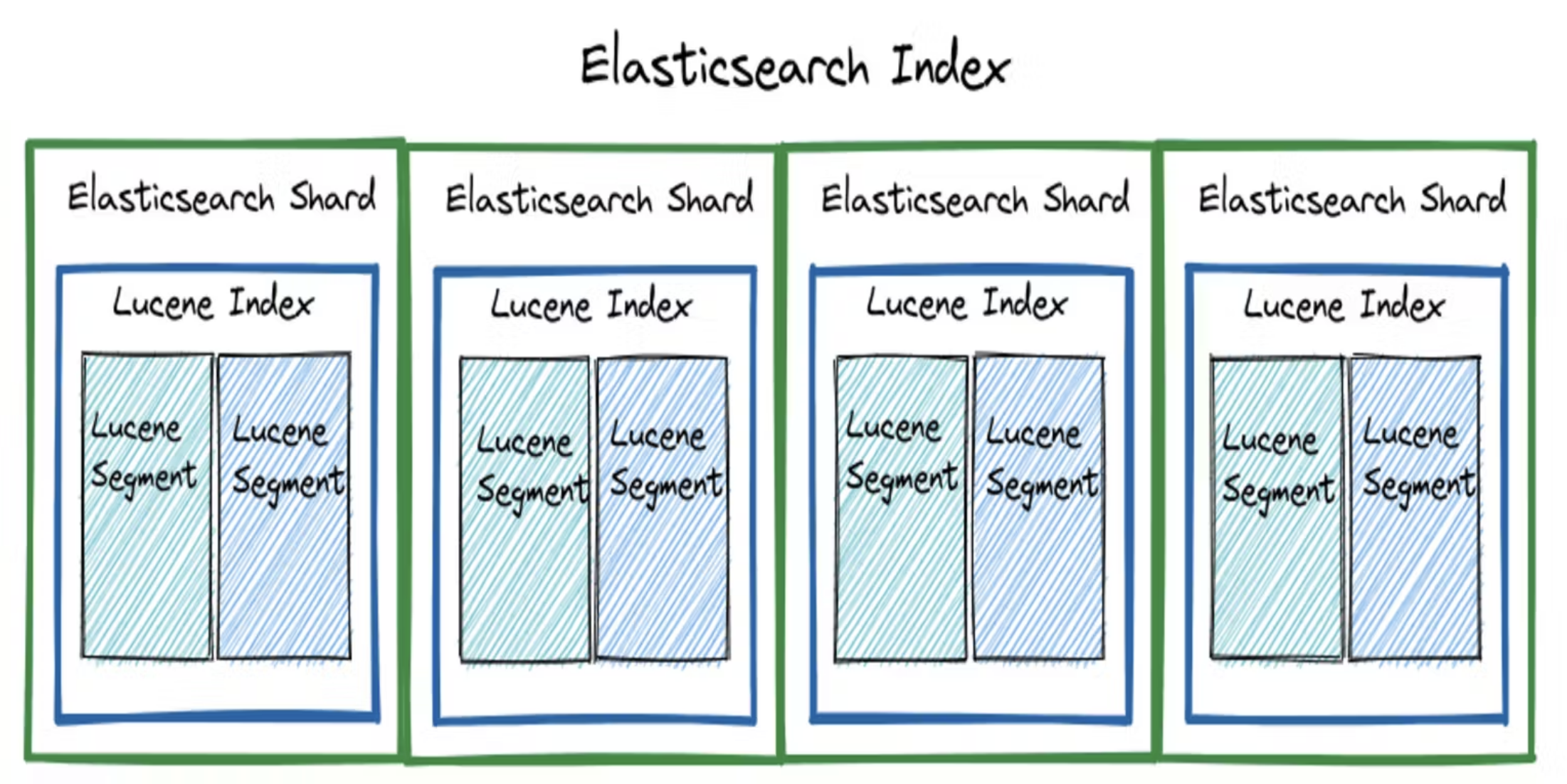 lucene - index
lucene - index
elasticsearch는 이런 shard를 apache-lucene 이라는 코어 라이브러리를 통해 구현하여 문서를 색인하고 검색합니다. 내부적으로 이 elastic - shard 는 lucene - index 를 단순히 wrapping 한 단위이며, lucene - index는 데이터가 기록되어 불변(immutable)인 상태에 해당하는 lucene - segment의 집합입니다. elasticsearh에 색인된 문서들은 결국 lucene - segment로 씌여지고 나서야 검색이 가능해집니다.
다시 정리해 보겠습니다.
- 데이터가 들어오면
lucene - segment가 Immuatable한 상태로 생성됩니다. - 이 segment들이 모여
lucene - index를 구성하고, 이 lucene index 들이 모여elastic - shard를 구성합니다. - 따라서 우리가 쿼리작업을 하기 위해서는 결국 내부적으로는
lucene - segment가 생성 완료되어야 하며, lucene - index에서는 불가능했던 분산 검색을 elasticsearch는elastic - shard라는 wrapping 단위로 한번 더 감싸 이를 여러 노드에 분산 배치함으로서 가능하게 만들었습니다.
적절한 샤드 구성
그렇다면 적절한 샤드 구성이란 무엇일까요? 이 질문은 두가지 내용으로 쪼개어 다시 질문할 수 있습니다.
- 적절한 샤드 크기는 얼마인가요?
- 적절한 샤드 개수는 몇개인가요?
결론부터 말씀드리면, 정해진 가이드는 없다. 가 지배적인 의견입니다. 이는 아키텍처 구성이나 데이터의 양, 쿼리 유형에 따라 적절한 구성이 달라질 수 있기 때문인데요, 엘라스틱에서는 그래도 적절한에 가.까.운. 가이드는 주고 있으며 내용은 아래와 같습니다.
Q: 적절한 샤드 크기는 얼마인가요?
샤드가 작으면 세그먼트가 작아져 오버헤드가 증가합니다. 평균 샤드 크기를 최소 몇 GB에서 수십 GB 사이로 유지하는 것을 목표로 하세요. 시계열 데이터가 있는 사용 사례의 경우 20GB에서 40GB 사이의 샤드가 일반적입니다.
Q: 적절한 샤드 개수와 Heap 사이즈는 얼마인가요?
데이터 노드의 인덱스당 필드당 1kB 힙 + 오버헤드를 허용하세요 각 매핑된 필드의 정확한 리소스 사용량은 그 유형에 따라 다르지만, 경험 법칙에 따르면각 데이터 노드가 보유한 인덱스당매핑된 필드당 힙 오버헤드를 약1kB까지 허용합니다. 또한 색인, 검색 및 집계와 같은 워크로드뿐만 아니라 Elasticsearch의 기준 사용에도 충분한 힙을 허용해야 합니다.0.5GB의 추가 힙은 많은 합리적인 워크로드에 충분하며, 워크로드가 크면 더 많이 필요하고 워크로드가 매우 적으면 훨씬 더 적은 양의 워크로드가 필요할 수 있습니다. 예를 들어, 데이터 노드가 각각 4,000개의 매핑된 필드를 포함하는 1,000개의 인덱스의 샤드를 보유하는 경우, 필드에 대해 약 1000 × 4000 × 1kB = 4GB 힙을 허용하고 그 워크로드 및 기타 오버헤드에 대해 추가로 0.5GB의 힙을 허용해야 합니다. 따라서 이 노드에는 4.5GB 이상의 힙 크기가 필요합니다.
위 내용을 고려하여 데이터의 총 크기를 적절한 샤드 크기 로 나누어 샤드의 수를 구합니다. 다만 구해진 샤드 수는 대략적인 추정치일 뿐 실제 환경에서는 성능 테스트와 모니터링을 통해 샤드 수를 조정해야 합니다. 또한, 샤드 분할과 병합 기능을 사용하여 샤드 구조를 지속적으로 최적화 하여야 합니다.
대략적인 계산 예시
예를 들어, 총 데이터 크기가 1TB(=1024GB)이고 샤드당 권장 크기를 30GB로 가정하면, 필요한 샤드 수는 1024GB / 30GB ≈ 34개의 샤드가 됩니다.
정리하며
이번 포스팅에서는 elasticsearch에서 샤드를 대략적으로 구성하기 위한 방법을 알아봤습니다.
- 샤드 크기는 최대 40GB 밑으로 유지합니다.
- 샤드 개수는 각 인덱스의 매핑 필드와 할당 가능한 힙 사이즈를 고려한 샤드 크기로 역산하여 결정하고, 지속적으로 개선해나갑니다.
참고문헌
- https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
- https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html#field-count-recommendation
- https://m.yes24.com/Goods/Detail/119719070
- https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html#field-count-recommendation