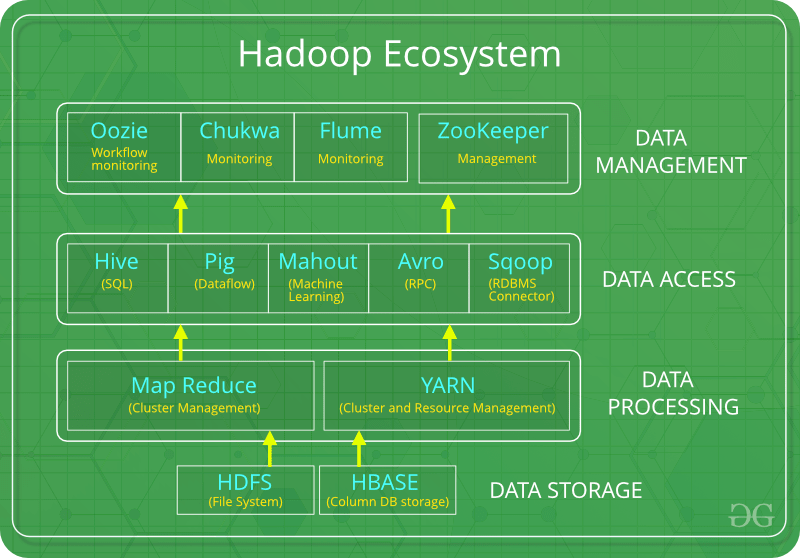
Apache Hadoop
Apache Hadoop은 대량의 데이터를 저장하고 계산을 수행하기 위한 오픈소스 소프트웨어 프로그래밍 프레임워크 입니다.
이번 포스팅에서는 HADOOP이 여러 버전을 거쳐 발전해 오면서 어떤 변화들이 있었는지 알아보도록 하겠습니다.
Hadoop Version 1
Main : HDFS + MAPREDUCE(Resource Management + Data Processing)
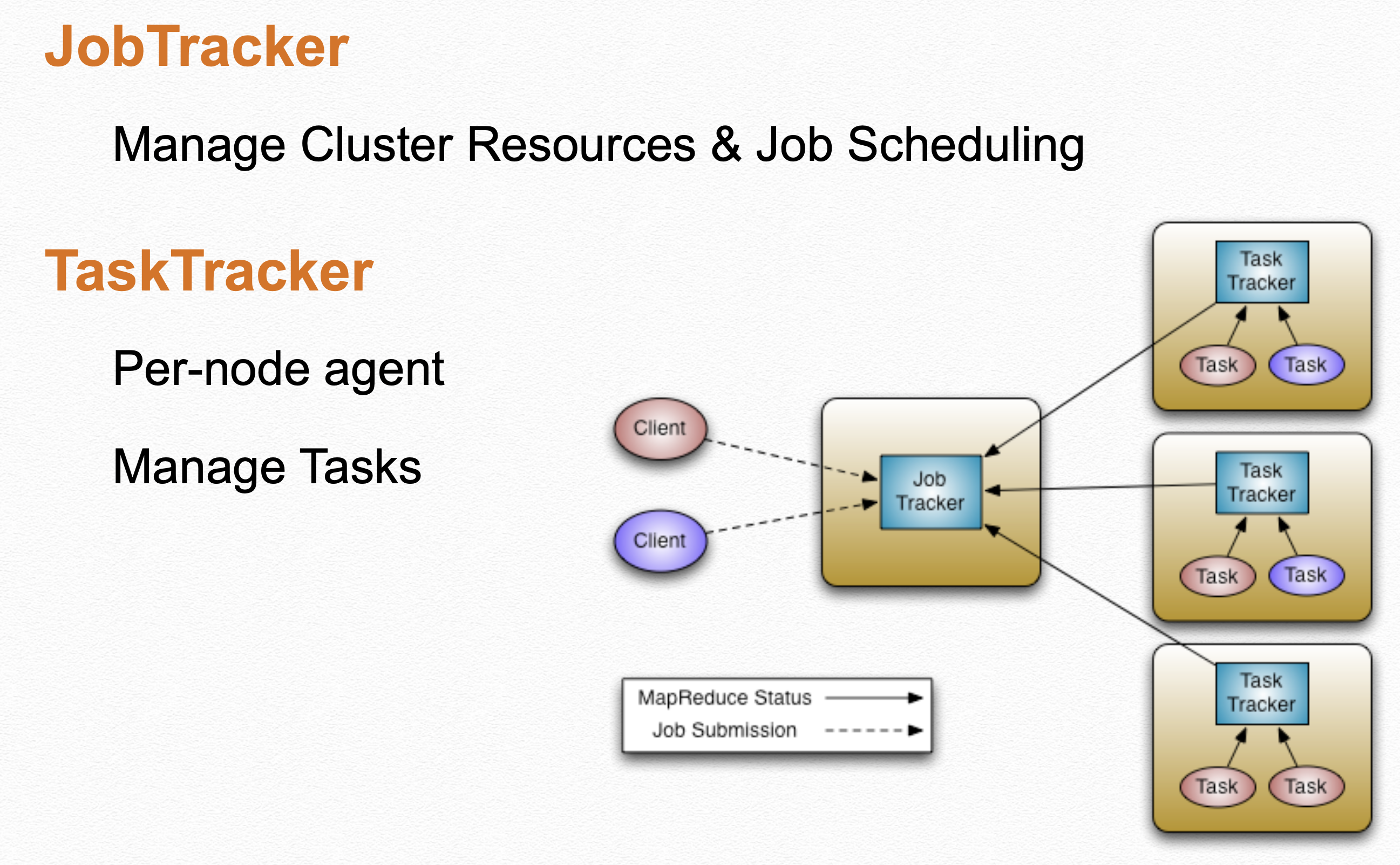 hadoop v1 architecture
hadoop v1 architecture
HADOOP 1은 하둡의 가장 초기 형태로 HDFS(하둡 분산 파일 시스템)와 MapReduce(자원 관리 및 데이터 처리)로 이루어져 있습니다. HADOOP 1 에서는 MapReduce 가 Resource-Management 와 Data-Processing 작업을 함께 수행합니다.
Hadoop 1의 동작방식은 다음과 같습니다.
Client에서 내용을 읽거나 쓰고 싶은 경우에 NameNode 에 이를 요청합니다.- MapReduce Job을 제출하는 경우에는 JobTracker를 요청하고, JobTracker는 이를 스케줄링하여 TaskTracker를 선정 한 뒤 전달합니다.
- 여기서
JobTracker는 메인 클러스터의 리소스와 잡스케줄링을 담당하고,TaskTracker는 각 노드와 담당 Task를 수행합니다.
하지만 아쉽게도 HADOOP 1은 다음과 같은 한계점들을 가지고 있었습니다.
- NameNode 가 단일 장애 지점입니다. 물론 Secondary NameNode가 존재하는 경우도 있지만, Sync 과정에 시간차가 발생하여 데이터 유실 가능성이 높아집니다.
- JobTracker 와 TaskTracker 의 부하가 너무 크게 발생합니다.
단일 실패 지점(single point of failure) 이란 ?
단일 실패 지점혹은단일 장애 지점은 시스템구성 요소 중에서 일부가 동작하지 않으면 전체 시스템이 중단되는 요소를 말합니다. Hadoop 2 이후부터는 NameNode의 다중화를 지원함으로서SPOF문제를 해결했습니다.
Hadoop Version 2
Main : HDFS + YARN + MAPREDUCE + Others
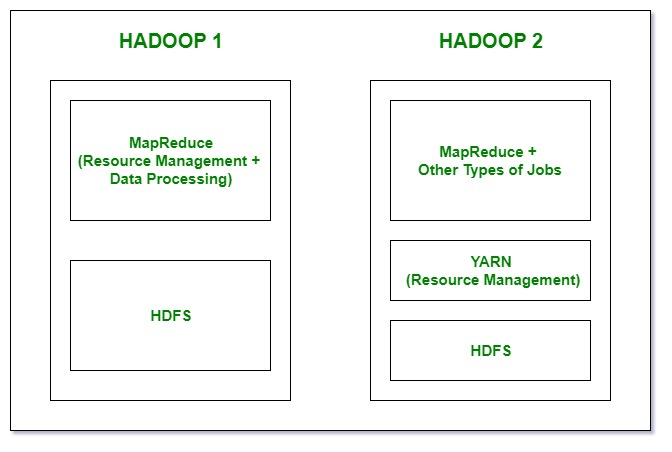 hadoop v과 v2의 구조적 차이
hadoop v과 v2의 구조적 차이 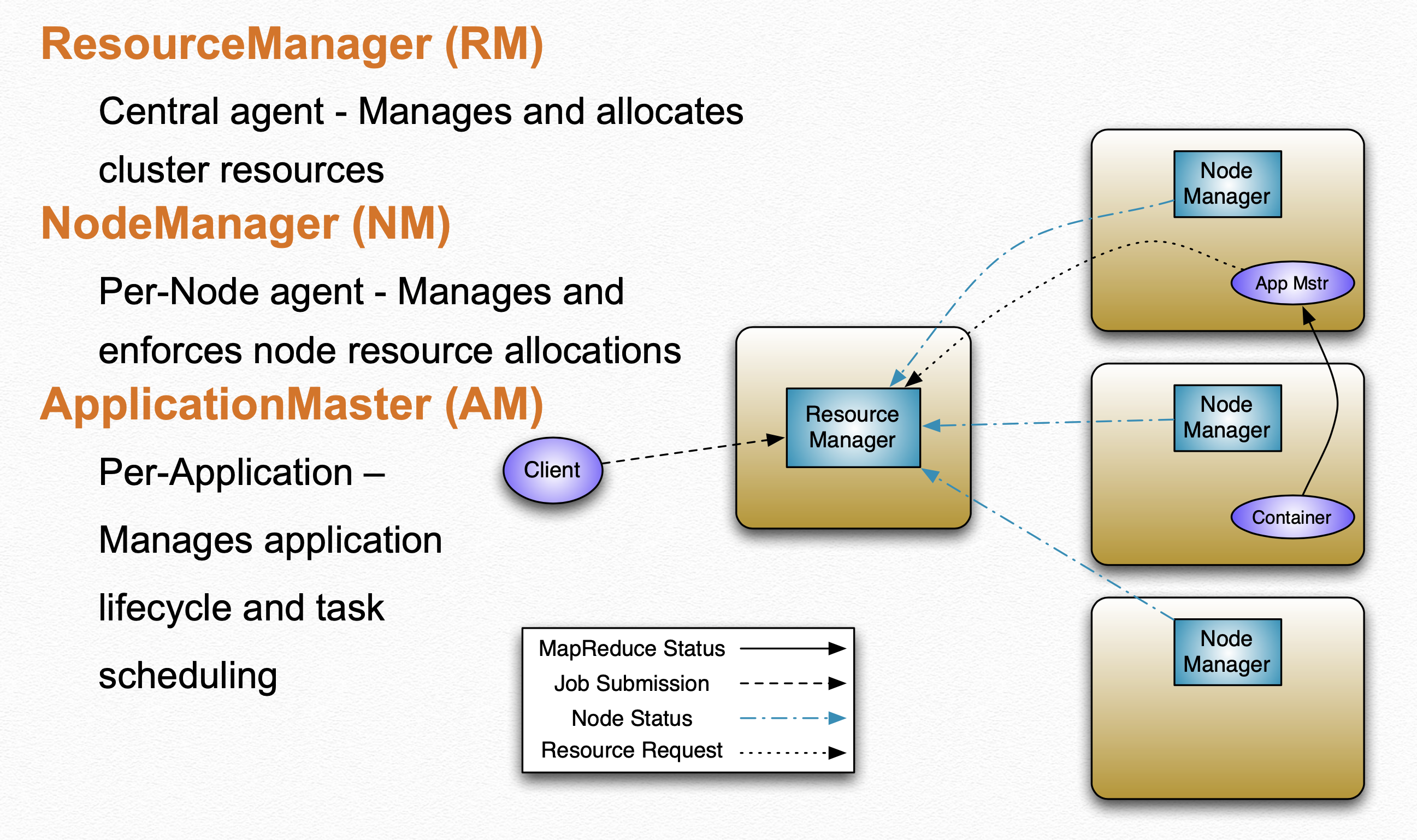 hadoop v2 architecture
hadoop v2 architecture
HADOOP 2는 HADOOP 1에서 보였던 SPOF나 부하 문제를 개선하기 위해 아래와 같은 개선점들이 추가되었습니다.
- 단일 장애 지점이였던 NamdeNode의 이중화(active-stanby)를 지원하게 되었습니다.
- JobTracker, TaskTracker 가 사라지고, 이를
ResourceManager와NodeManager가 대체하게 되었습니다. 또한 NodeManager 는Container와 ApplicationMaster 로 구성됨으로써 다양한 작업을 지원할 수 있게 되었습니다.
Hadoop Version 3
Main : HADOOP2 And More
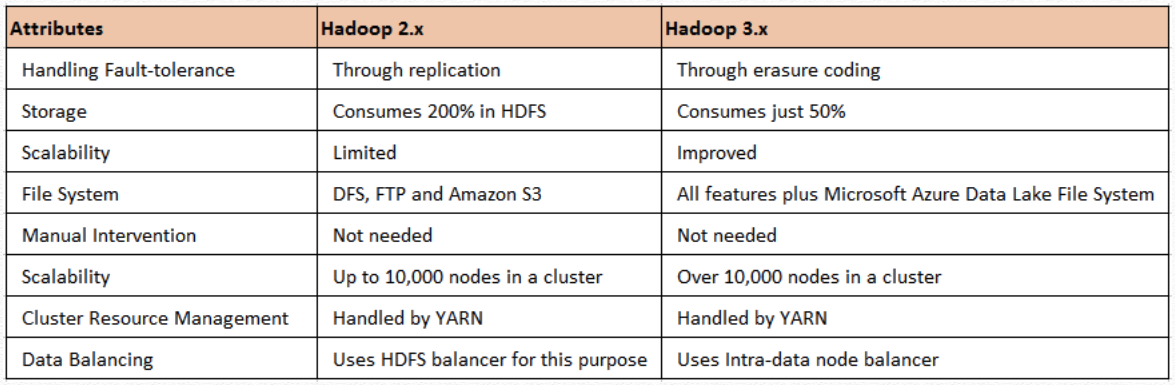 hadoop v2 & v3
hadoop v2 & v3
그렇다면 HADOOP 3에서는 어떤 변화가 있었을까요?
HADOOP 3에서는 HADOOP 2와 구성요소는 동일하지만 다양한 기능들이 추가되었습니다.
- Erasure-Codin을 지원하게 되었습니다. 이전 HDFS에서는 replica가 3이라면 그만큼의 디스크 공간을 차지해야 했지만, 그보다 적은 공간으로도 같은 수의 복제본을 유지할 수 있게 되었습니다.
- YARN Timeline Service v2가 도입되게 됩니다. application의 일반적인 정보를 RestAPI를 통해 조회하는데 이를 개선하여 더 다양한 퍼포먼스를 지원하게 되었습니다.
- 최소 지원하는 JAVA 버진이 JAVA 8 로 업그레이드 되었습니다.
- NameNode 이중화 기능이 더 강화되었습니다. 사실 HADOOP 2에서의 NameNode 이중화는 정말
2개의 이중화를 의미합니다. 하지만HADOOP 3에서는2개 이상의 NameNode 지원하게 되었습니다.
다음 포스팅에서는 이어서 HDFS 와 YARN 에 대해 얘기해 보도록 하겠습니다.