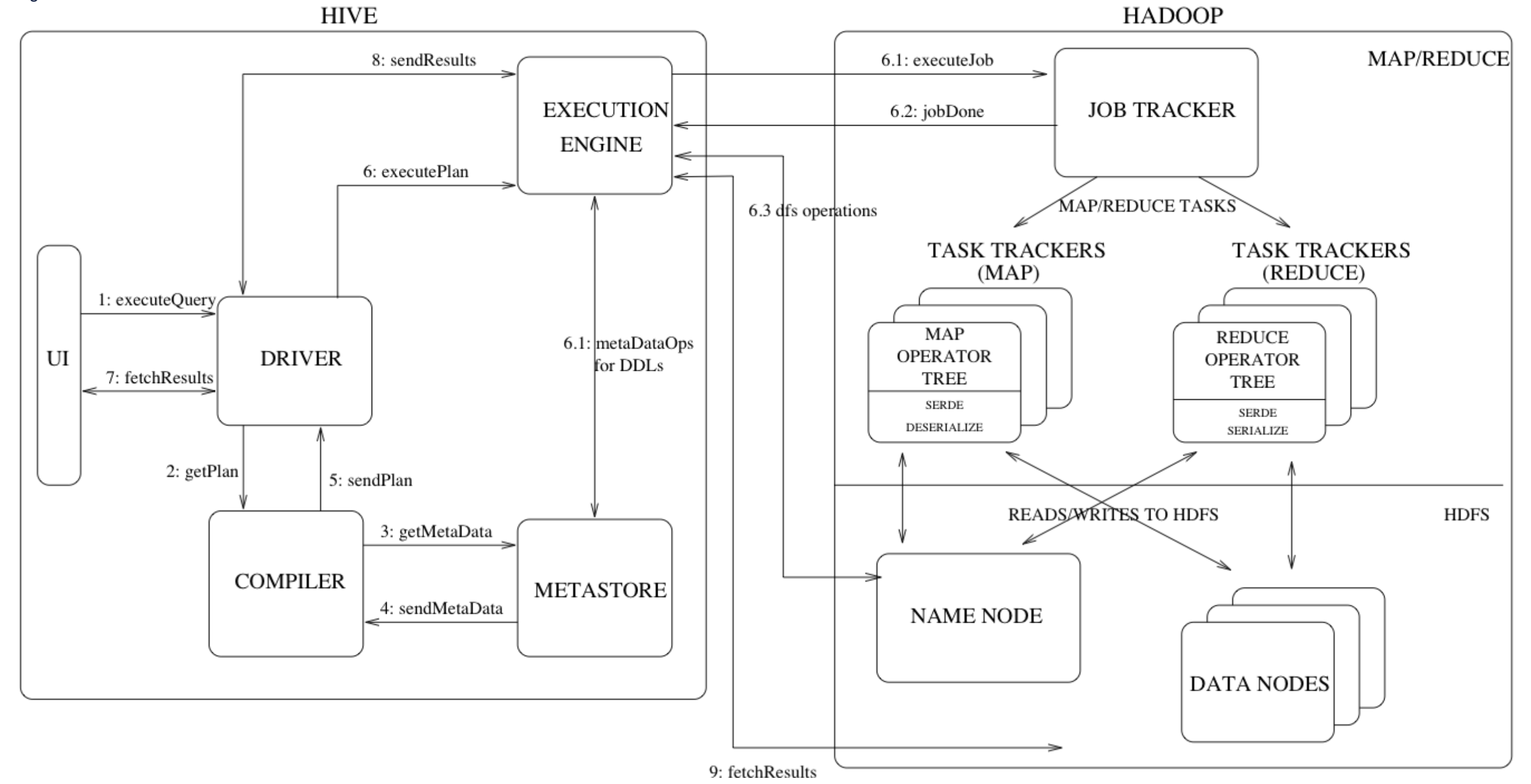
들어가며
이번 포스팅에서는 Apache Hive™ 의 성능을 개선하기 위한 여러 방법을 알아보고 정리하는 시간을 가져보려고 합니다. 공식 문서에서 확인할 수 있듯이, Apache Hive는 분산 스토리지에서 대용량의 데이터는 SQL로 질의하기 위한 소프트웨어 입니다.
The Apache Hive™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
Hive의 특징으로는 아래 6가지가 설명되어 있는데, 이 중에서 쿼리 엔진인 MapReduce, Àpache Tez, 그리고 data format 에 대해 집중적으로 살펴 볼 예정입니다. 또한 대화형 질의를 위한 LLAP(Low Latency Analytical Processing) 도 함께 알아보도록 하겠습니다.
- Tools to enable easy access to data via SQL, thus enabling data warehousing tasks such as extract/transform/load (ETL), reporting, and data analysis.
- A mechanism to impose structure on a variety of
data formats - Access to files stored either directly in Apache HDFS™ or in other data storage systems such as Apache HBase™
- Query execution via
Apache Tez™, Apache Spark™, or `MapReduce - Procedural language with HPL-SQL
- Sub-second query retrieval via Hive
LLAP, Apache YARN and Apache Slider.
실행 엔진 비교 [MR, Tez, Spark]
본격적으로 들어가기에 앞서, Hive의 특징 중 Query execution 부분을 정리하고 넘어가겠습니다. 통상 Hive에서 쿼리 엔진은 기본 map-reduce(mr) 를 비롯하여, Àpache Tez, Àpache Spark 이렇게 3가지 종류가 지원됩니다. 각각의 특징을 정리해보면 다음과 같습니다.
Hive on MR 가장 기본적인 형태의 엔진입니다. 초창기 Hive의 기본 실행 엔진으로서(2.x 버전부터 Tez로 변경), Hadoop의 MapReduce 프레임워크를 사용하여 데이터를 배치 처리합니다. 대규모의 장기적인 데이터 처리에 안정적인 성능을 보이지만 쿼리 집계 단계가 늘어날수록
Disk IO가 빈번하게 발생하여 속도가 느려지는 단점이 있습니다.Hive on Tez Tez는 YARN을 기반으로,
DAG(Directed Acyclic Graph)구조를 사용하여Disk IO를 줄이고 메모리 기반의 연산을 지원하여 성능을 크게 개선했습니다. 때문에 Hive의 기본 엔진으로 자리잡았으며 배치와 대화형 쿼리 모두 준수한 성능을 보여줍니다. 다만 몇몇 추가적인 설정이 필요하며 MapReduce 보다는 메모리 사용량이 많습니다.Hive on Spark Spark를 Hive의 실행엔진으로 사용할 수 도 있습니다. Spark는 인메모리(In-Memory) 데이터 처리를 기반으로 한 엔진이므로 DataFrame을 메모리에 저장하여 MR, Tez에 비해 매무 빠른 처리를 가능하게 합니다. 데이터를 메모리에 상주시키는 만큼 자원은 많이 소모하지만 빠른 처리 성능이 필요한 경우 좋은 선택지가 될 수 있습니다.
개인 프로젝트에서는 이 자원 이슈로 Spark가 아닌 Tez를 배치 작업을 위한 실행 엔진으로 선택했습니다.
Hive 읽기 성능 개선하기
엔진에 상관없이 Hive 에서는 아래 튜팅 작업으로 성능을 향상시킬 수 있습니다. 이 중에서 저는 읽기(Read)에 대한 튜닝 & 테스트를 진행해볼 예정이고 나머지 쓰기, 수정, 삭제 작업의 경우는 관련 내용을 참조 부탁드립니다. 데이터는 성능확인이 어느정도 가능한 최소 용량을 채우기 위해 다음 예시 데이터 를 사용했습니다. 데이터 사이즈는 총 58837669 ROW / 11.73 GB 입니다.
[ select query & query plan ] 1차
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
/* [query] */
select
from airline
where 1=1
and Year=1987
and DepDelay > 0
order by DepDelay desc
limit 10;
/* [query plan] */
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: airline
Statistics: Num rows: 40830928 Data size: 125922582528 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((UDFToDouble(year) = 1987.0D) and (UDFToDouble(depdelay) > 0.0D)) (type: boolean)
Statistics: Num rows: 6805154 Data size: 20987095031 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: year (type: string), month (type: string), dayofmonth (type: string), dayofweek (type: string), deptime (type: string), crsdeptime (type: string), arrtime (type: string), crsarrtime (type: string), uniquecarrier (type: string), flightnum (type: string), tailnum (type: string), actualelapsedtime (type: string), crselapsedtime (type: string), airtime (type: string), arrdelay (type: string), depdelay (type: string), origin (type: string), dest (type: string), distance (type: string), taxiin (type: string), taxiout (type: string), cancelled (type: string), cancellationcode (type: string), diverted (type: string), carrierdelay (type: string), weatherdelay (type: string), nasdelay (type: string), securitydelay (type: string), lateaircraftdelay (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27, _col28
Statistics: Num rows: 6805154 Data size: 20987095031 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col15 (type: string)
sort order: -
Statistics: Num rows: 6805154 Data size: 20987095031 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string), _col7 (type: string), _col8 (type: string), _col9 (type: string), _col10 (type: string), _col11 (type: string), _col12 (type: string), _col13 (type: string), _col14 (type: string), _col16 (type: string), _col17 (type: string), _col18 (type: string), _col19 (type: string), _col20 (type: string), _col21 (type: string), _col22 (type: string), _col23 (type: string), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col27 (type: string), _col28 (type: string)
Execution mode: vectorized
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: string), VALUE._col1 (type: string), VALUE._col2 (type: string), VALUE._col3 (type: string), VALUE._col4 (type: string), VALUE._col5 (type: string), VALUE._col6 (type: string), VALUE._col7 (type: string), VALUE._col8 (type: string), VALUE._col9 (type: string), VALUE._col10 (type: string), VALUE._col11 (type: string), VALUE._col12 (type: string), VALUE._col13 (type: string), VALUE._col14 (type: string), KEY.reducesinkkey0 (type: string), VALUE._col15 (type: string), VALUE._col16 (type: string), VALUE._col17 (type: string), VALUE._col18 (type: string), VALUE._col19 (type: string), VALUE._col20 (type: string), VALUE._col21 (type: string), VALUE._col22 (type: string), VALUE._col23 (type: string), VALUE._col24 (type: string), VALUE._col25 (type: string), VALUE._col26 (type: string), VALUE._col27 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27, _col28
Statistics: Num rows: 6805154 Data size: 20987095031 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 10
Statistics: Num rows: 10 Data size: 30840 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 10 Data size: 30840 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: 10
Processor Tree:
ListSink
최초 SQL문을 Beeline으로 Yarn cluster 에 Job을 제출했을 때 182.323s 가 소요되었습니다…🤦🏻♂️ Job History Server 에서 map tasks, reduce shuffle bytes 등을 확인해 보면 locality 도 높았고 shuffle 단계에서의 네트워크 부하도 거의 없었지만 속도가 매우 느립니다.


이 상태에서 읽기 작업의 성능 튜닝으로 아래 작업들을 진행해보도록 하겠습니다.
질의한 select 쿼리가 jobhistory server에서 조회되지 않는다면?
Hive beeline 에서 질의한 sql 문이 간단한 질의인 경우에는 Local에서 수행되기 때문에 그 기록이 남지 않습니다.EXPLAIN으로 쿼리 플랜을 조회해 보면 확인해볼 수 있는데요,yarn을 통해 job을 제출하게 하면 수행 이력을 확인할 수 있습니다.
Partition Pruning (파티션 절감)
자주 조회하는 특정 열을 기준으로 데이터를 파티션하면 불필요한 데이터를 스캔하지 않아 조회 속도가 빨라집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CREATE EXTERNAL TABLE airline_temp (
Month int,
DayofMonth int,
DayOfWeek int,
...
NASDelay int,
SecurityDelay int,
LateAircraftDelay int
)
PARTITIONED BY (year int)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS TEXTFILE
LOCATION "hdfs://dfs-cluster/user/hive/warehouse/default.db/airline_csv";
ALTER TABLE airline_partition_temp ADD PARTITION (year=1987);
[ select query & query plan ] 2차
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
/* [query] */
select *
from airline_partition_temp
where 1=1
and year=1987
and DepDelay > 0
order by DepDelay desc
limit 10;
/* [query plan] */
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: airline_partition_temp
Statistics: Num rows: 425577 Data size: 1271626420 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (UDFToDouble(depdelay) > 0.0D) (type: boolean)
Statistics: Num rows: 141859 Data size: 423875473 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: month (type: string), dayofmonth (type: string), dayofweek (type: string), deptime (type: string), crsdeptime (type: string), arrtime (type: string), crsarrtime (type: string), uniquecarrier (type: string), flightnum (type: string), tailnum (type: string), actualelapsedtime (type: string), crselapsedtime (type: string), airtime (type: string), arrdelay (type: string), depdelay (type: string), origin (type: string), dest (type: string), distance (type: string), taxiin (type: string), taxiout (type: string), cancelled (type: string), cancellationcode (type: string), diverted (type: string), carrierdelay (type: string), weatherdelay (type: string), nasdelay (type: string), securitydelay (type: string), lateaircraftdelay (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 141859 Data size: 423875473 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col14 (type: string)
sort order: -
Statistics: Num rows: 141859 Data size: 423875473 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string), _col7 (type: string), _col8 (type: string), _col9 (type: string), _col10 (type: string), _col11 (type: string), _col12 (type: string), _col13 (type: string), _col15 (type: string), _col16 (type: string), _col17 (type: string), _col18 (type: string), _col19 (type: string), _col20 (type: string), _col21 (type: string), _col22 (type: string), _col23 (type: string), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col27 (type: string)
Execution mode: vectorized
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: string), VALUE._col1 (type: string), VALUE._col2 (type: string), VALUE._col3 (type: string), VALUE._col4 (type: string), VALUE._col5 (type: string), VALUE._col6 (type: string), VALUE._col7 (type: string), VALUE._col8 (type: string), VALUE._col9 (type: string), VALUE._col10 (type: string), VALUE._col11 (type: string), VALUE._col12 (type: string), VALUE._col13 (type: string), KEY.reducesinkkey0 (type: string), VALUE._col14 (type: string), VALUE._col15 (type: string), VALUE._col16 (type: string), VALUE._col17 (type: string), VALUE._col18 (type: string), VALUE._col19 (type: string), VALUE._col20 (type: string), VALUE._col21 (type: string), VALUE._col22 (type: string), VALUE._col23 (type: string), VALUE._col24 (type: string), VALUE._col25 (type: string), VALUE._col26 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 141859 Data size: 423875473 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 10
Statistics: Num rows: 10 Data size: 29880 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col5 (type: string), _col6 (type: string), _col7 (type: string), _col8 (type: string), _col9 (type: string), _col10 (type: string), _col11 (type: string), _col12 (type: string), _col13 (type: string), _col14 (type: string), _col15 (type: string), _col16 (type: string), _col17 (type: string), _col18 (type: string), _col19 (type: string), _col20 (type: string), _col21 (type: string), _col22 (type: string), _col23 (type: string), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col27 (type: string), 1987 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27, _col28
Statistics: Num rows: 10 Data size: 29880 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 10 Data size: 29880 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
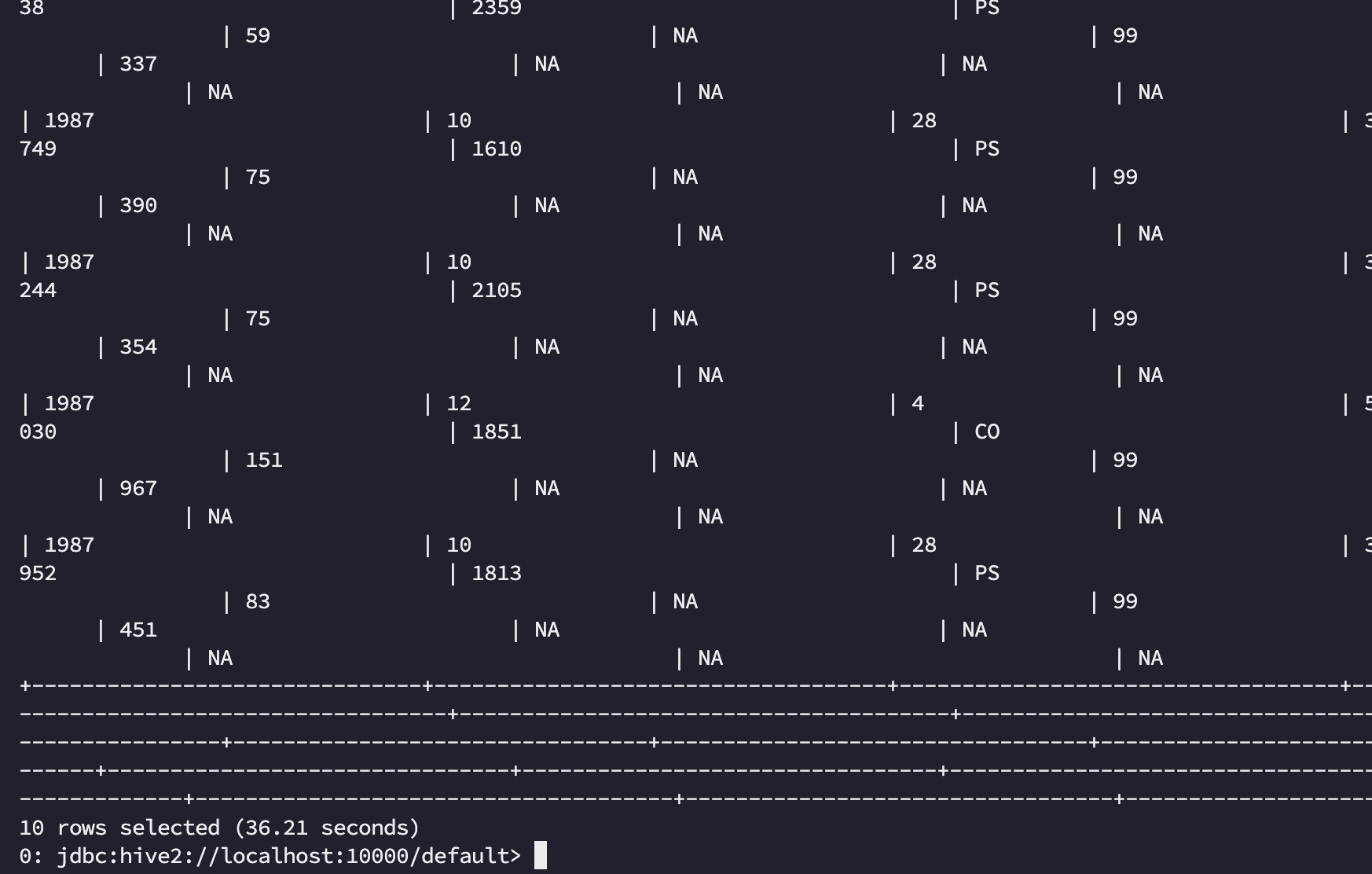
map, reduce 횟수가 한번으로 줄었고 수행 시간은 36.21s 로 줄어들었습니다.
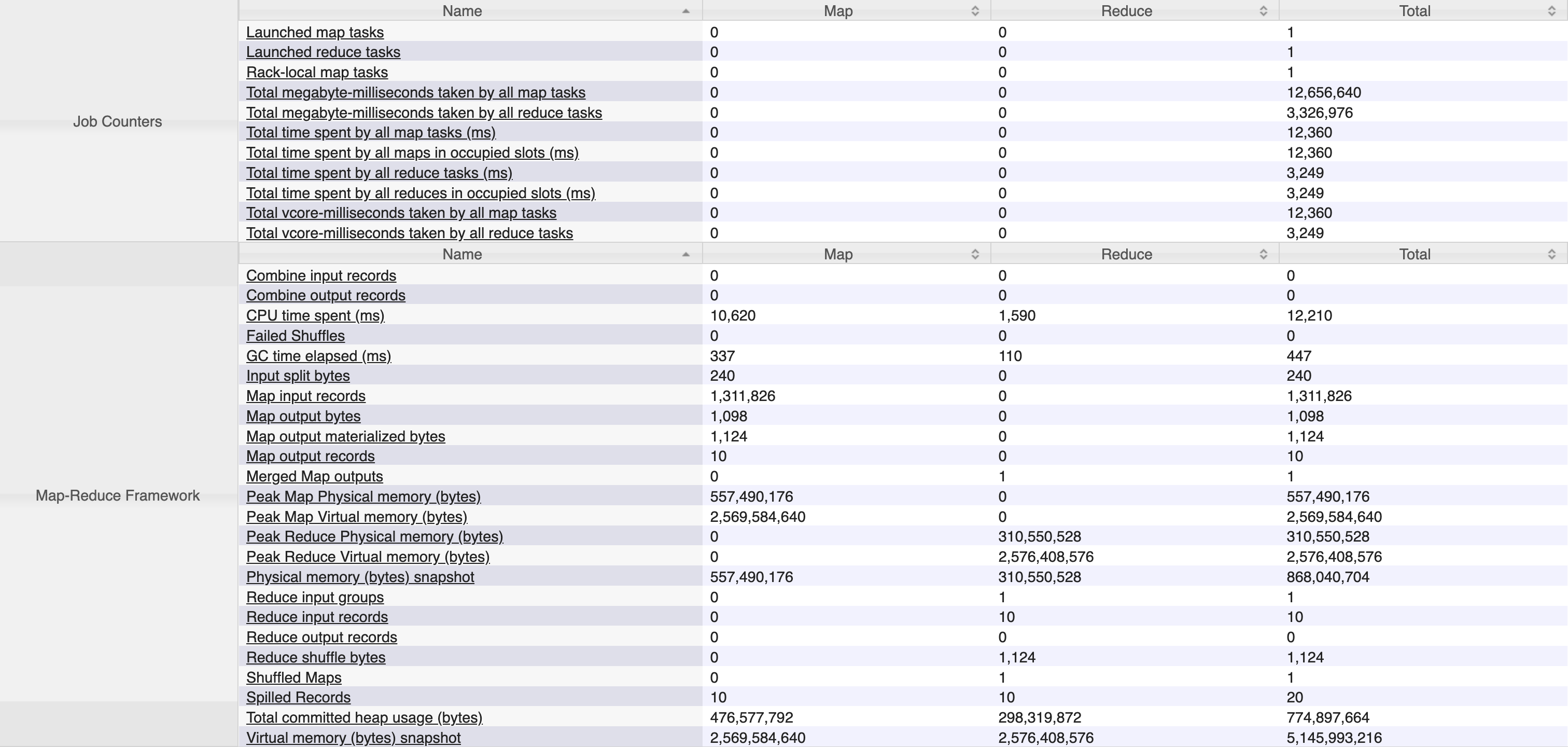
MSCK REPAIR TABLE명령어를 사용하면 Hive가 지정된 경로에서 누락된 파티션을 자동으로 인식하고 메타스토어에 추가합니다.
1
2
3
4
5
6
7
-- MSCK REPAIR TABLE 명령어로 추가하기
MSCK REPAIR TABLE airline_partition_temp;
-- 수동으로 partition 추가하는 경우(예시)
ALTER TABLE your_table_name
ADD PARTITION (partition_column1=value1, partition_column2=value2)
LOCATION 'hdfs://path/to/your/partition/directory';
File Format 최적화
ORC, Parquet와 같은 컬럼형 저장 형식을 사용하면, 필요한 컬럼만을 읽을 수 있어 성능이 개선됩니다. Hive에서 데이터를 효율적으로 저장하고 읽기 위해 ORC 포맷 및 압축을 사용할 수 있습니다. ORC 파일 포맷은 열 기반 저장 방식으로, MapReduce 작업에서 디스크 I/O와 메모리 사용을 크게 줄일 수 있습니다. 압축을 설정하면 디스크 사용량과 I/O가 줄어 성능이 개선됩니다. 다만 저는 .csv 파일 형태로 데이터를 저장하고, 이를 hive table 로 만드는 과정이 있었으므로 중간에 .csv 파일을 orc 포맷 테이블로 변환하는 과정을 추가했습니다.
OpenCSVSerde로 생성하는 경우- 장점: CSV 파일의 데이터 로드가 간단하고 직관적입니다. 데이터를 바로 읽고 쓰는 데 용이하며, 초기 로드 시 변환 과정 없이 테이블 생성이 가능합니다.
- 단점: CSV는 컬럼형 포맷이 아니므로 데이터 처리 성능이 떨어지고, 압축 효율도 낮습니다. 특히 대규모 데이터를 반복적으로 조회하거나 분석할 때 성능이 저하될 수 있습니다.
OrcSerde로 생성하는 경우- 장점: ORC 포맷은 컬럼형 데이터 포맷으로 설계되어 조회 및 집계 성능이 매우 뛰어나며, 압축 효율도 높습니다. ORC는 필요한 컬럼만을 읽을 수 있어 대량 데이터의 쿼리 성능이 향상됩니다.
- 단점: CSV 데이터를 ORC로 변환하는 과정이 필요하므로, 초기 데이터 로드 시 변환 작업이 발생합니다. 특히, 변환에 따른 추가적인 CPU와 I/O 비용이 소요됩니다.
따라서 OpenCSVSerde 방식으로 읽은 TEXT 형태의 데이터를 ORC 포맷 테이블로 다시 저장해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
CREATE TABLE airline_partition (
Month int,
DayofMonth int,
DayOfWeek int,
DepTime int,
...
CarrierDelay int,
WeatherDelay int,
NASDelay int,
SecurityDelay int,
LateAircraftDelay int
)
PARTITIONED BY (year int)
STORED AS ORC;
INSERT INTO TABLE airline_partition
PARTITION (year)
SELECT * FROM airline_partition_temp;
동적 파티션(Dynamic Partitioning)을 사용중이라면?
동적 파티션(Dynamic Partitioning)을 기본 설정에서 사용하고 있었다면, hive partitioning 에서는 최소 하나의 정적 파티션(Static Partition) 이 필요하기 때문에 아래 에러가 발생할 수 있습니다.
Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column.
따라서hive.exec.dynamic.partition.mode=nonstrict설정으로 동적 파티션을 완전히 허용해 줍니다.
file format을 옮겨쓰는 작업은 대략 5mins 54sec 가 소요되었고, reduce task 가 눈에 띄게 늘어났습니다. 파일 포맷까지 변경하고 난 뒤에 동일 쿼리의 실행속도는 27.064sec 가 소요되었습니다. 특이한 점은 동일 쿼리를 수행시켰을 때 map, reduce 작업이 각 1회씩만 이루어졌다는 점입니다. 이를 통해 partition pruning 과 orc file-format 이 굉장히 효율적으로 동작하고 있음을 확인할 수 있었습니다.
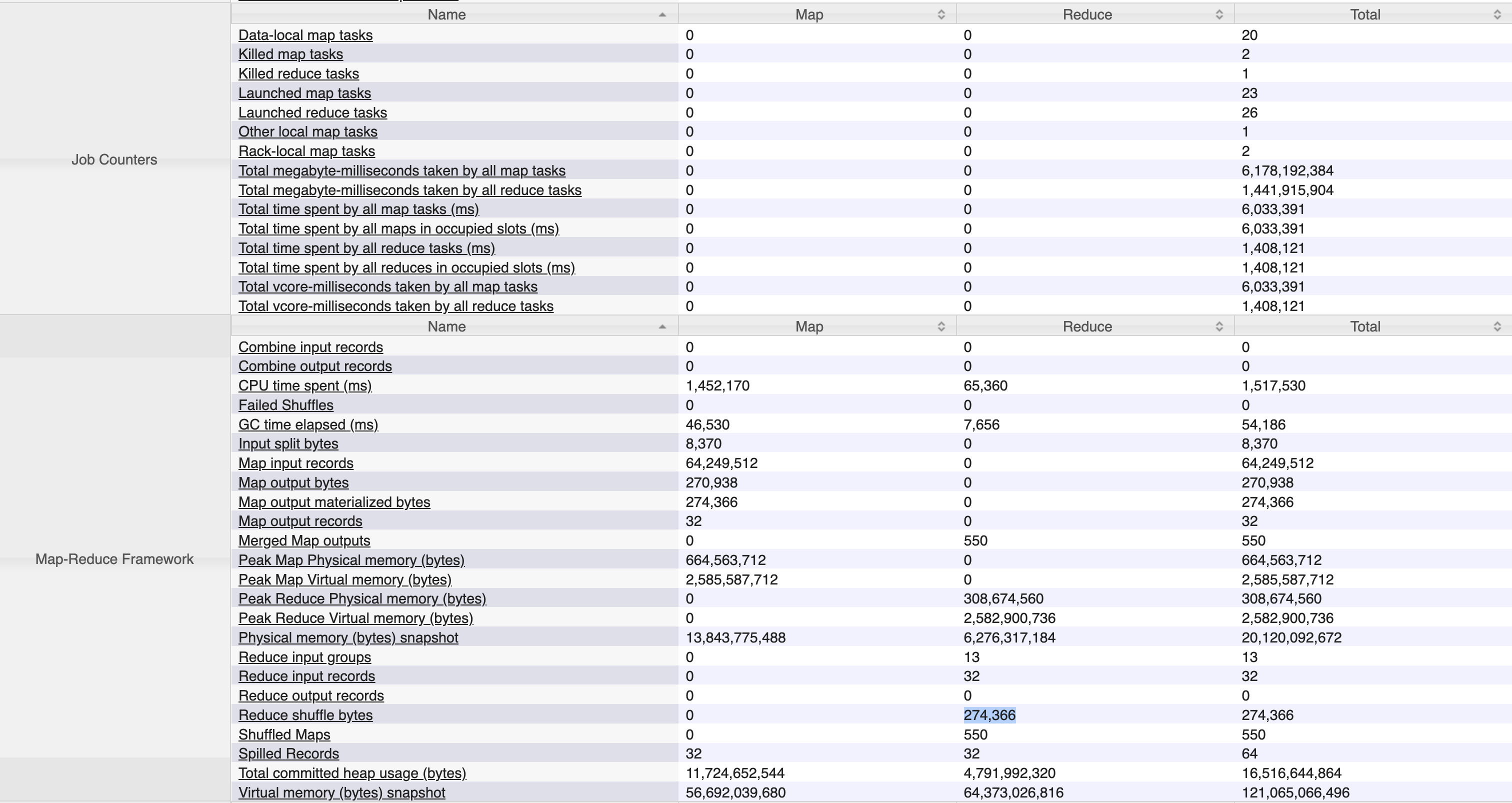

여기서는 hive 에 별도 압축 옵션을 설정하지 않았습니다. orc 는 기본적으로 압축되지 않은 형태로 데이터를 저장하는데요, TBLPROPERTIES ("orc.compress"="SNAPPY"); 같은 옵션을 table 생성시에 부여하면 압축도 추가할 수 있습니다.
각 시간대별로 수행 이력과 자원 사용률을 확인하고자 yarn application history server와 간단한 grafana 모니터링도 켜 두었었는데요, partitioning 작업 이전에는 단순 select 만 해도 자원 사용률이 치솟던 것이 partitioning, orc 적용 후에는 자원을 거의 사용하지 않는 것이 확인되었습니다. 다만 text 포맷을 orc로 변환하여 insert 하는 과정에서는 제일 많은 자원이 소비되는 경향이 보였습니다.
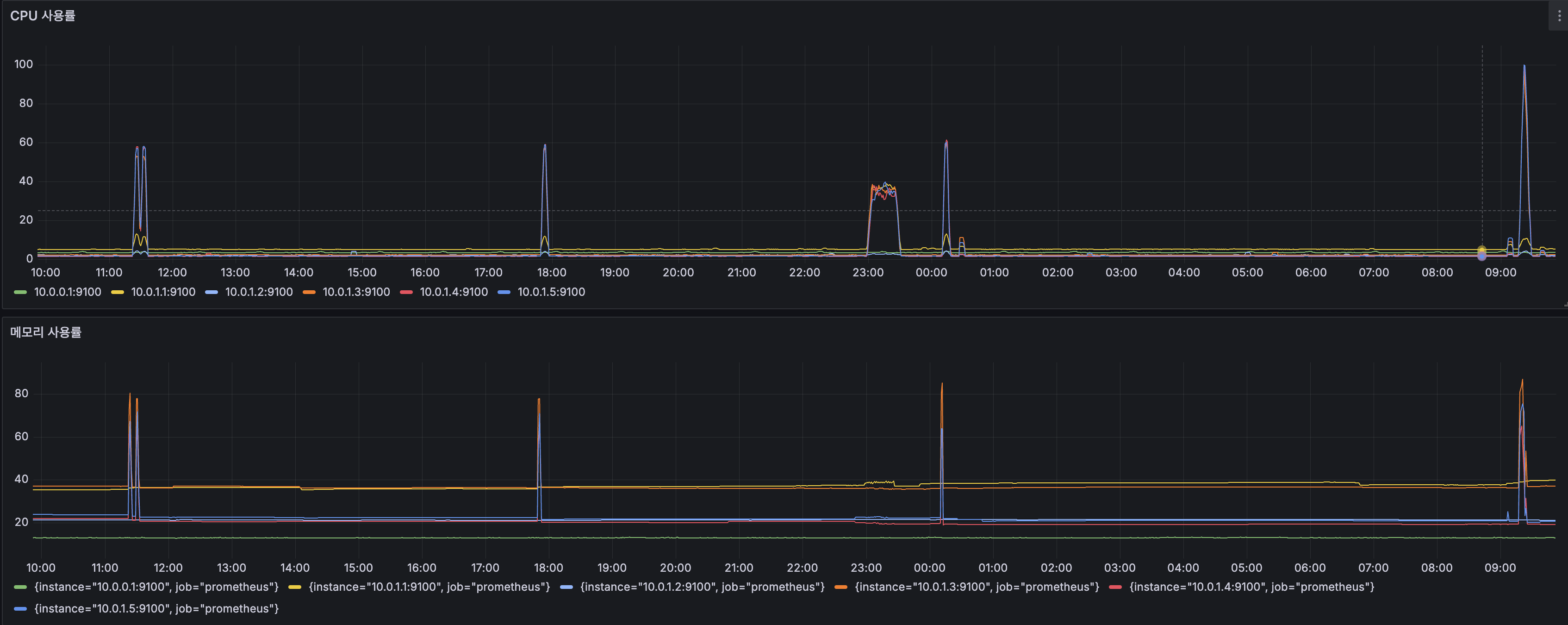
Bucket 사용
제일 많이 사용하는 Partition, File-Format 외에도 성능 개선을 위한 다양한 방법이 있습니다. 대표적으로는 Bucket 이 있는데요, 데이터가 특정 컬럼에 따라 버킷으로 나뉘어 있으면, join 이나 group by 연산에서 맵/리듀스 태스크의 수를 줄임으로서 성능을 개선할 수 있습니다. (이후 등장하는 방법들은 따로 적용하진 않았습니다.)
1
2
3
4
5
6
CREATE TABLE bucketed_table
(
id INT,
name STRING
)
CLUSTERED BY (id) INTO 10 BUCKETS;
Join 최적화
Hive에서 Join 쿼리는 성능 저하의 주요 원인 중 하나입니다. EXPLAIN 명령어를 통해 Join이 많은 리듀스 태스크를 유발하고 있음을 확인할 수 있습니다. 작은 테이블과 큰 테이블 간의 조인을 실행할 때에 MapJoin을 사용하면 성능을 개선할 수 있습니다. 작은 테이블을 메모리에 로드하고, 이를 맵 단계에서 조인하는 방식으로 리듀스 단계를 건너뛰어 성능을 개선합니다. MAPJOIN 힌트를 사용하여 작은 테이블을 메모리에 로드하도록 유도할 수 있습니다. 이를 통해 작은 테이블을 자동으로 메모리에 로드하여 맵 조인으로 처리할 수 있습니다.
1
set hive.auto.convert.join=true;
1
2
3
SELECT /*+ MAPJOIN(small_table) */ *
FROM large_table
JOIN small_table ON large_table.id = small_table.id;
Vectorization (백터화)
Vectorization Hive 쿼리 실행 시 성능을 크게 향상시키는 기능입니다. 벡터화는 데이터를 배치 단위로 처리하여 I/O와 CPU 사용량을 줄이고, 대용량 데이터를 더 빠르게 처리할 수 있게 합니다. 벡터화 활성화 방법은 아래와 같습니다. 벡터화 처리는 테이블의 데이터 타입이나 쿼리 패턴에 따라 성능이 크게 향상될 수 있습니다.
1
2
set hive.vectorized.execution.enabled=true;
set hive.vectorized.execution.reduce.enabled=true;
Hive 쓰기, 수정 & 삭제 개선하기
Hive 에서의 쓰기, 수정 및 삭제 에 대한 개선 방법도 정리하여 기록해 둡니다. 쓰기 작업에서의 성능개선은 유의미하겠지만 Hive 로 수정이나 삭제는 권장하지 않는 방법이라 참고 정도만 하시면 될 것 같습니다.
쓰기(Write) 작업 튜닝 방법
쓰기 작업에서는 데이터 로드와 저장의 효율성을 높이는 것이 중요합니다. 대규모 데이터를 저장할 때 디스크 I/O가 많이 발생하므로 다음과 같은 방법을 적용합니다.
- 적절한 파일 형식 선택: 데이터를 압축하여 저장할 수 있는 ORC, Parquet 파일 형식을 선택하면 저장 효율을 높일 수 있으며, 읽기 작업에도 유리합니다.
- 파일 크기 조정: 쓰기 작업 시 파일이 너무 작은 경우 병렬 처리 성능이 저하될 수 있으므로, 적절한 파일 크기로 저장될 수 있도록
hive.merge.smallfiles.avgsize와 같은 설정을 조정합니다. - 압축 사용: 데이터를 압축하여 저장하면 저장 공간을 절약할 수 있습니다.
SET hive.exec.compress.output=true;및SET mapreduce.output.fileoutputformat.compress=true;와 같은 설정으로 압축을 적용할 수 있습니다. - 병렬 처리 최적화:
hive.exec.parallel을 활성화하여 병렬 처리를 늘림으로써 쓰기 작업의 성능을 향상시킬 수 있습니다.
수정(Update) 작업 튜닝
Hive는 본래 배치 작업에 최적화된 데이터 웨어하우스라 실시간 업데이트 작업에 최적화되지 않았기 때문에 다른 엔진과 비교하면 업데이트가 상대적으로 느립니다. 하지만 ACID 기능을 통해 업데이트가 가능하며, 다음과 같은 방법을 통해 성능을 개선할 수 있습니다.
- 소수의 레코드만 변경: 대규모 데이터에 대한 업데이트는 성능에 큰 영향을 미치므로 필터링을 통해 최소한의 레코드만 수정하도록 제한합니다.
- Vacuum과 Compaction: 업데이트가 반복되는 테이블은
Compaction을 주기적으로 수행하여 작은 파일을 병합하고 성능을 최적화할 수 있습니다.
삭제(Delete) 작업 튜닝(거의 사용하지 않음)
- partition 을 활용한 삭제 최적화
- ORC 형식과 Compaction 사용
- ACID 지원 테이블에서 삭제를 수행하려면 ORC 형식을 사용하는 것이 좋습니다. ORC는 컬럼형 포맷이므로 삭제 시 I/O가 적게 발생하고, 성능이 더 높습니다.
- Compaction 주기적 수행: ACID 테이블에서 삭제가 이루어지면 작은 파일들이 많이 생성되는데, 이로 인해 성능이 저하될 수 있습니다.
Compaction(압축)을 주기적으로 수행하여 작은 파일을 병합하고, 성능을 개선할 수 있습니다.hive.compactor.initiator.on과 같은 설정을 통해 주기적인 Compaction을 자동으로 수행하도록 합니다.
- 트랜잭션 관리 최적화
일괄 삭제: 자주 발생하는 작은 단위의 삭제보다는 일괄 삭제를 통해 트랜잭션을 줄입니다.트랜잭션 롤백 최소화: ACID 테이블에서 삭제 후 롤백은 최소화 합니다.
추가) 맵 사이즈와 리듀스 단계 최적화
너무 작은 맵 태스크는 과도한 태스크 생성으로 인해 오버헤드가 발생할 수 있습니다. 이를 방지하기 위해 입력 파일의 크기를 적절하게 조정하여 너무 많은 task가 생성되지 않도록 설정합니다.
1
2
3
# 설정을 통해 맵 태스크의 적절한 크기를 설정할 수 있으며, 너무 많은 태스크가 생성되지 않도록 합니다.
set mapreduce.input.fileinputformat.split.maxsize=256000000;
set mapreduce.input.fileinputformat.split.minsize=128000000;
정리하며
막상 내용을 작성하다 보니 내용이 너무 길어져 가장 중요한 Tez 와 관련된 내용은 다음 포스팅으로 넘기기로 했습니다… 그리고 sql 및 쿼리플랜은 숨김기능으로 넣으려 했는데 jekyll theme 커스텀이 git action 버전이랑 꼬여서 쉽지 않네요 😅. 다음 시간에는 Hive on Tez 에 대한 개요와 설치 및 빌드 방법, 그리고 Tez 에서의 성능 개선 방안을 가지고 돌아오도록 하겠습니다. 👋
참고문헌
- https://cwiki.apache.org/confluence/display/Hive/Home
- https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
- https://docs.cloudera.com/runtime/7.2.18/hive-performance-tuning/hive_performance_tuning.pdf
- https://community.cloudera.com/t5/Community-Articles/Tips-and-best-practices-for-optimizing-Hive-performance/ta-p/385637
- https://blog.contactsunny.com/data-science/optimising-hive-queries-with-tez-query-engine#google_vignette