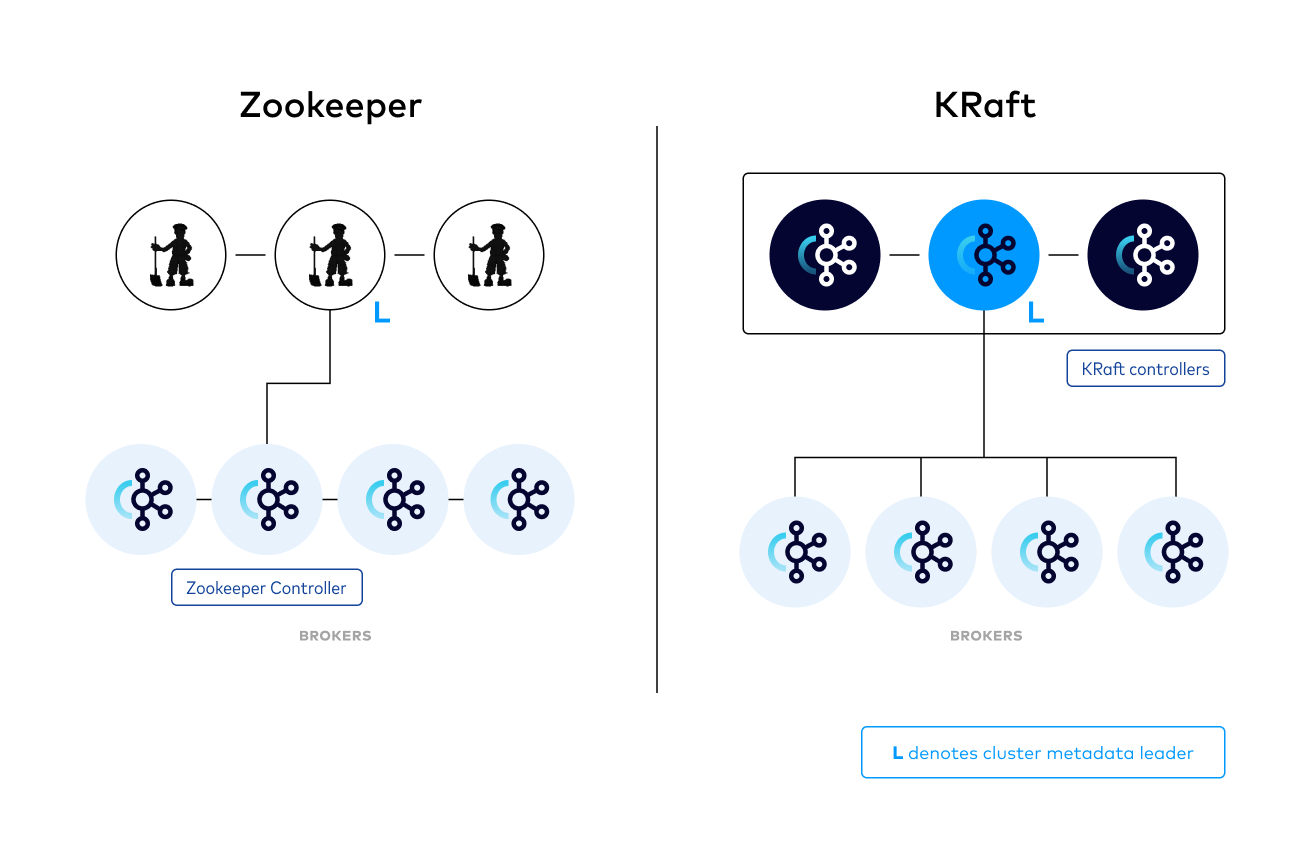
들어가며
Kafka는 여태까지 Apache ZooKeeper 를 사용하여 클러스터의 메타데이터 를 관리해 왔습니다. 그러다가 Zookeeper로의 의존성을 제거하고 메타데이터를 kafka 가 자체적으로 관리하는 KIP-500 제안이 발의되었고, Apache Kafka 3.3(프로덕션) 버전 이후에는 본격적으로 KRaft(Kafka Raft) 가 도입되었습니다. 이번 포스팅에서는 기존 Zookeeper Mode 와 Kraft Mode 의 차이점을 살펴보고자 합니다.
#1. Kafka & Zookeeper
먼저 Zookeeper 가 kafka cluster를 관리했던 방법에 대해 알아보도록 하겠습니다. Zookeeper는 분산 코디네이션 서비스를 제공하는 오픈소스 프로젝트입니다. 여기에서 분산 코디네이션이란, 분산 프로세스간의 경쟁 조건 (Race Condition) 및 교착 상태 (Deadlock) 등을 핸들링 하여 네임스페이스(표준 파일 시스템과 유사하게 구성)를 통해 서로 조정할 수 있도록 하는 것을 말합니다. 이 네임스페이스 는 ZooKeeper 용어로 ZNode 라고 하는 데이터 레지스터로 구성되며, 이는 파일 및 디렉토리와 유사합니다.
Metadata in ZNode
Kafka를 Zookeeper Mode 로 사용하게 되면 이 ZNode 에 Kafka의 메타정보가 보관되게 됩니다. 그 구조는 다음과 같습니다.
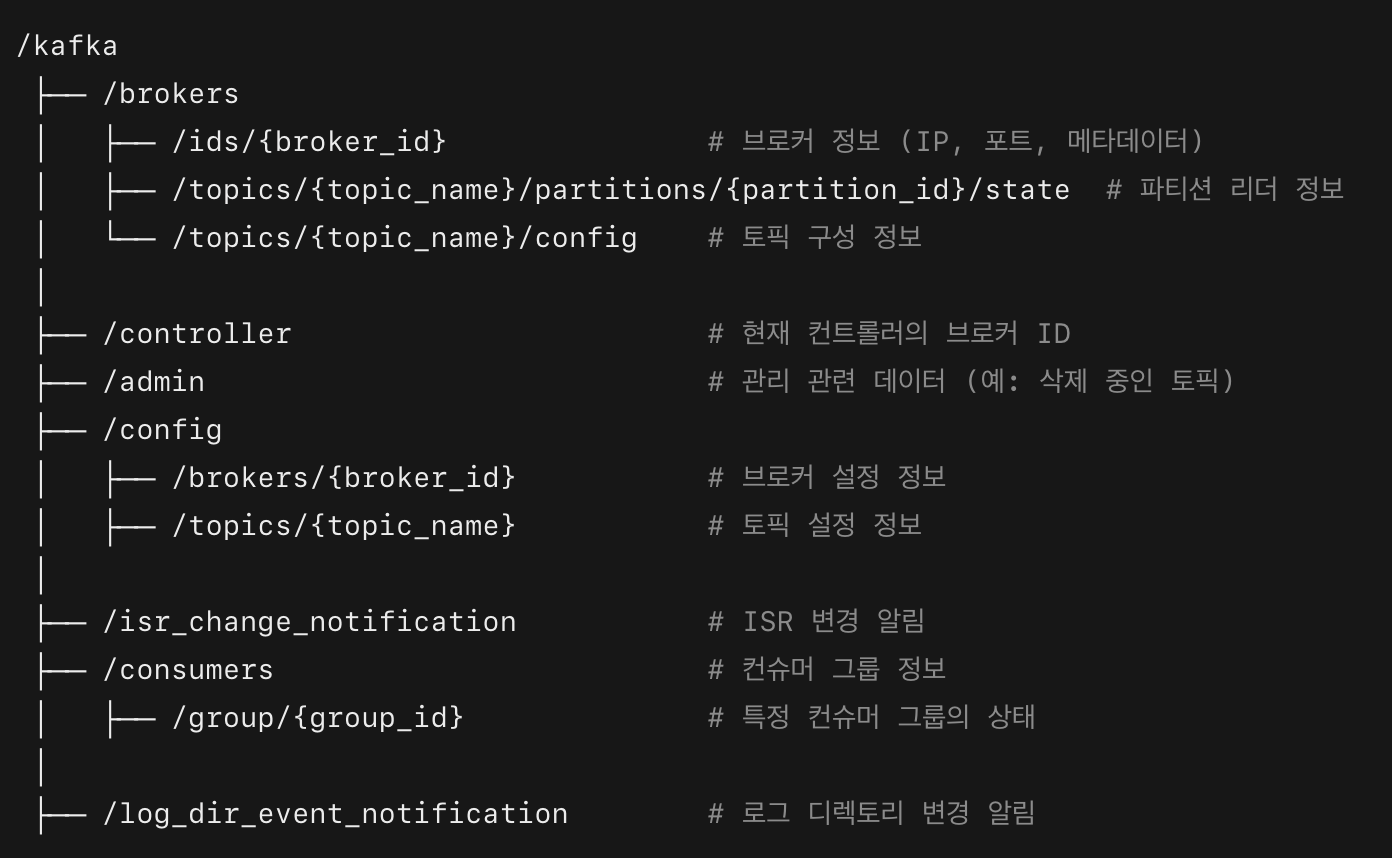 ZNode for kafka
ZNode for kafka
위 ZNode 가 가지고 있는 메타데이터 정보 는 다음과 같습니다.
- /brokers/ids/{broker_id}
- 현재 클러스터에 속한 브로커의 정보(IP, 포트, 메타데이터)를 저장
- /brokers/topics/{topic_name}/partitions/{partition_id}/state
- 각 토픽의 파티션 리더, ISR(In-Sync Replica), Replicas 정보 저장
- /controller
- 현재 컨트롤러 역할을 담당하는 브로커 ID 저장
- /config/topics/{topic_name}
- 특정 토픽의 구성 정보 저장
- /consumers/{group_id}
- 특정 컨슈머 그룹의 오프셋과 파티션 할당 상태 관리
Zookeeper 의 역할
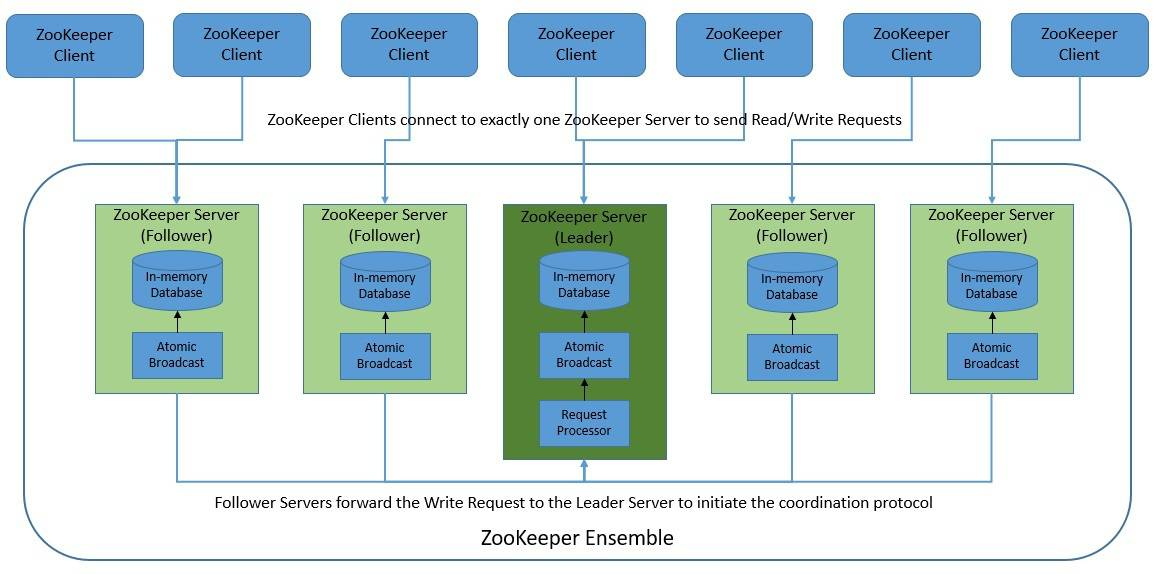 Zookeper in kafka cluster
Zookeper in kafka cluster
Zookeeper는 ZNode에 저장한 Kafka의 메타데이터를 통해 아래의 역할들을 수행합니다.
- 브로커 등록 및 상태 관리
- Kafka 브로커가 시작되면 ZooKeeper에 자신을 등록하고 주기적으로
heartbeat을 전송하여 정상 상태를 유지합니다. - 브로커가 비정상 종료되면 ZooKeeper가 이를 감지하고 클러스터에서 제거합니다.
- Kafka 브로커가 시작되면 ZooKeeper에 자신을 등록하고 주기적으로
- 토픽 및 파티션 메타데이터 저장
- Kafka의 토픽, 파티션 정보, 리더/팔로워 브로커 정보 등이 ZooKeeper의
ZNode에 저장됩니다.
- Kafka의 토픽, 파티션 정보, 리더/팔로워 브로커 정보 등이 ZooKeeper의
- 컨트롤러 선출 (Leader Election)
- Kafka는 클러스터에서 한 개의 컨트롤러(Controller)를 선출하는데, ZooKeeper의
ephemeral znode(*ZooKeeper에서 일시적으로 유지되는 ZNode(노드)) 를 활용하여 동적으로 컨트롤러를 결정합니다. - 컨트롤러가 장애가 발생하면 ZooKeeper가 자동으로
새로운 컨트롤러를 선출합니다.
- Kafka는 클러스터에서 한 개의 컨트롤러(Controller)를 선출하는데, ZooKeeper의
- ACL 및 구성 관리
- Kafka의 보안 정책, 접근 제어 목록(ACL) 정보도 ZooKeeper에서 관리할 수 있습니다.
- 동적 설정 변경
- Kafka
브로커와토픽 설정을 ZooKeeper를 통해 변경할 수 있으며, 변경된 설정이 브로커에 전파됩니다.
- Kafka
결론적으로 Kafka Cluster의 특정 Broker의 Controller 즉, Controll Plane 에 붙어서 메타데이터를 관리하고 각 브로커의 상태관리, 컨르롤러 선출 등의 핵심 역할을 Zookeeper가 대신 해주고 있었습니다.
#2. Kafka & KRaft
KRaft Mode에서는 이런 Zookeeper의 역할을 kafka broker 내부에서 대체했습니다. KRaft 는 Kafka 와 Raft 를 합친 단어인데요, Raft 는 메타데이터 관리를 위해 ZooKeeper에 대한 Kafka의 종속성을 제거하기 위해 도입된 합의 프로토콜 입니다. 이는 ZooKeeper와 Kafka라는 두 가지 다른 시스템을 요구하고 구성하는 대신 메타데이터에 대한 책임을 Kafka 자체로 통합하여 Kafka의 아키텍처를 크게 단순화합니다. KRaft는 다음과 같은 장점을 가지고 있습니다.
- Kafka 에 대한 관리, 배포가 단순해진다.
- Kafka cluster 를 수백만개의 파티션으로 확장이 가능하다.
- Kafka 의 안정성, 장애 조치 성능이 향상된다. (복구 시간도 굉장히 짧아진다.)
Metadata in KRaft
이번에는 KRaft가 메타데이터를 관리하는 구조를 알아보겠습니다. KRaft 모드에서는 dedicated mode(전용모드 혹은 shared mode(공유모드) 두가지가 있는데요, Controller 역할을 하는 Broker를 별도로 두는 것이 dedicated mode 입니다. controller와 broker 가 공유하는 경우는 shard mode 라고 합니다. 아래 이미지는 shard mode 의 kafka kraft 아키텍쳐를 보여주고 있습니다.
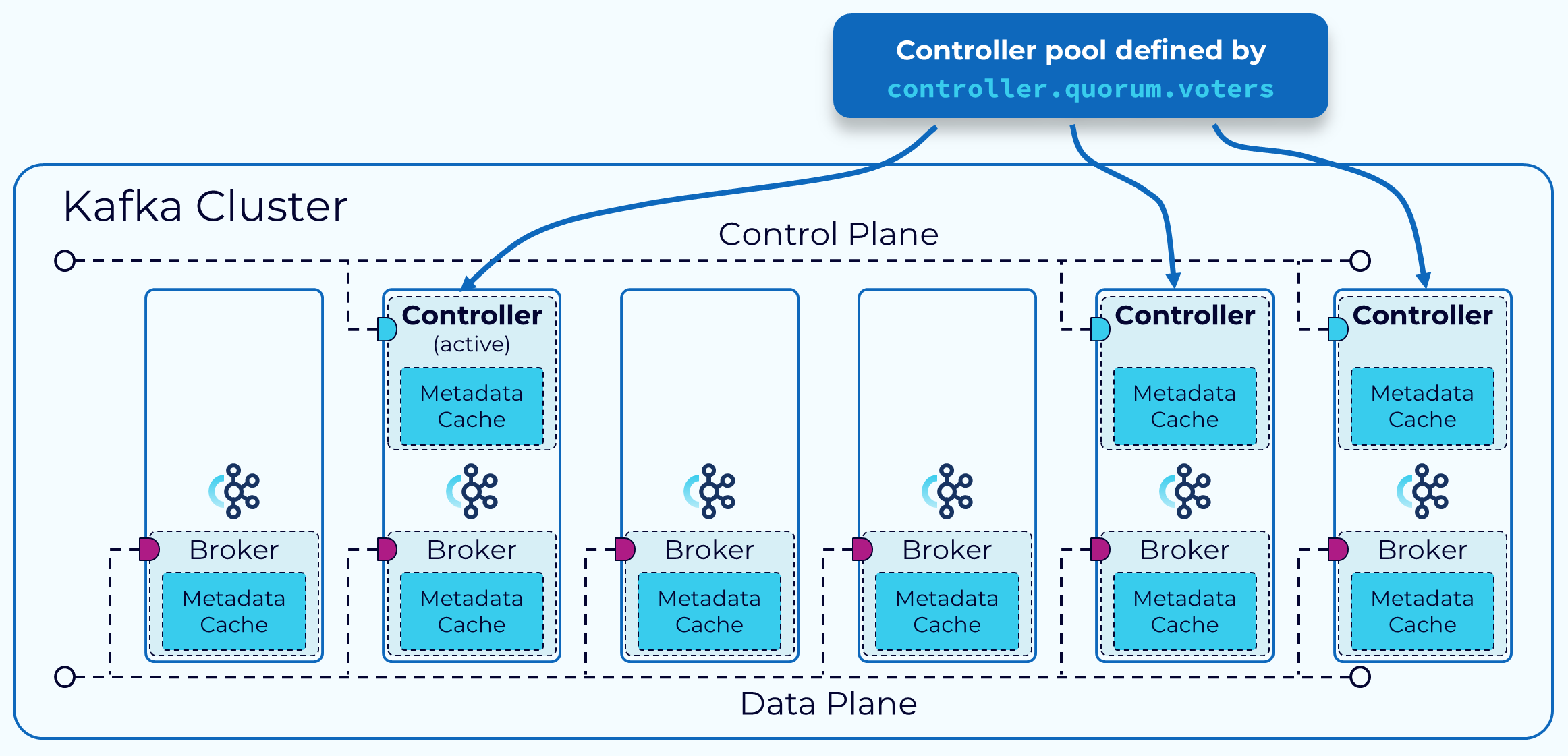 KRaft Design
KRaft Design
위의 KRaft 디자인을 보면 Kafka의 장점을 잘 살려서 Zookeeper를 대체하고 있습니다.
- 컨트롤러 브로커 중 하나는 활성 컨트롤러가 되고, 이 활성 컨드롤러가 다른 브로커와 메타데이터에 대한 변경 사항을 통신하게 됩니다.
- 모든 컨트롤러 브로커는 최신 상태로 유지되는 메모리 내
메타데이터 캐시를 유지 관리하기 때문에 필요한 경우 모든 컨트롤러가 활성 컨트롤러로 인계할 수 있는데요, Zookeeper의 경우는 별도로 띄운 노드 개수만큼만 쿼럼을 유지할 수 있는 반면 KRaft는 kafka broker 전부를 (shared mode인 경우)controller.quorum.voters, 즉 쿼럼 후보군에 포함시킬 수 있기 때문에 훨씬 안정적입니다.
- 모든 컨트롤러 브로커는 최신 상태로 유지되는 메모리 내
- Kafka 답게(?) 메타데이터는
Topic에 저장합니다.- KRaft 모드에서 모든 컨트롤러 관리 리소스의 현재 상태를 반영하는 클러스터 메타데이터는
__cluster_metadata라는 단일 파티션 Kafka 토픽에 저장합니다. KRaft는 이 토픽을 사용하여 컨트롤러와 브로커 노드에서 클러스터 상태 변경을 동기화합니다. 이 토픽에서 리더는 활성화된 컨트롤러, 팔로워는 다른 컨트롤러들이 됩니다. 이 상태에서 활성화된 컨트롤러가 다른 컨트롤러나 브로커에 메타데이터 변경 사항을 브로드캐스트하는 대신, 각각 변경 사항을복제(패치)합니다. 이를 통해 모든 컨트롤러와 브로커를동기화 상태로 유지하는 것이 매우 효율적이며, 브로커와 컨트롤러의 재시작 시간도 단축됩니다.
- KRaft 모드에서 모든 컨트롤러 관리 리소스의 현재 상태를 반영하는 클러스터 메타데이터는
정리하며
이번 포스팅에서는 Kafka 의 Zookeeper mode 와 KRaft mode 의 차이점을 알아보고 각 모드에서 kafka cluster의 메타데이터를 어떤식으로 관리하는지 알아봤습니다. 사실 Zookeeper 에서 KRaft로의 마이그레이션을 테스트 해보려고 포스팅을 시작했는데 내용이 길어져서 다음 포스팅에서 한번 다뤄보도록 하겠습니다.👋
참고문헌
- https://developer.confluent.io/learn/kraft/
- https://docs.confluent.io/platform/current/kafka-metadata/kraft.html#kraft-overview
- https://docs.confluent.io/platform/current/installation/migrate-zk-kraft.html
- https://zookeeper.apache.org/doc/r3.5.1-alpha/zookeeperOver.html
- https://developer.confluent.io/courses/architecture/control-plane/