
들어가며
지난 포스팅 에서는 spark on yarn 과 spark on kubernetes 의 차이점을 알아보고, 이를 구성하는 세가지 방법을 알아보았습니다. 세 방법을 정리해보면 다음과 같습니다.
첫번째 방법은
Native Kubernetes Integration을 사용하는 방법입니다.
다른 용어로Kubernetes Native Mode라고도 합니다. AWS EKS, Google GKE, Azure AKS 같은 클라우드 Kubernetes 환경에서 Spark을 실행할 때 주로 많이 사용하며 클라우드 네이티브 환경에서 리소스를 효율적으로 관리할 수 있다는 장점이 있습니다.리소스 최적화,단발성 Spark Job 실행의 경우에 자주 활용됩니다.두번쨰 방법은
Spark Operator를 사용하는 방법입니다.
Airflow, Kubeflow, Argo Workflows 같은 워크플로우 오케스트레이션 시스템과 함께 사용할 때나 Spark 를Kubernetes Native방식으로 완전히 자동화하려고 할 때 많이 사용합니다.kubectl apply -f spark-application.yaml방식으로 Spark Job을 Kubernetes의 리소스 형태로 관리 가능하고 운영 및 유지보수가 쉽다는 장점이 있습니다.반복적인 Spark Job 관리,자동화의 경우에 자주 활용됩니다.세번째 방법은 kubernetes 에
Spark Standalone Mode를 구축하는 방법입니다.
이는 실무에서 잘 사용되는 방법은 아닙니다. Kubernetes의 리소스 스케줄링 기능을 거의 활용할 수 없고 Spark Master/Worker를 Kubernetes에서 직접 관리해야 하므로 운영 부담이 크기 때문입니다.
이번 포스팅에서는 1) Native Kubernetes Integration, 2) Spark Operator 각각을 간단하게 실행해보고 이를 정리해두려고 합니다.
Kubernetes 네이티브 모드 (Native Kubernetes Mode)
Step 1. (원격) kubernetes cluster 접속
저는 로컬에서 테스트해봤는데 마침 사이드 프로젝트를 하여 구축해둔 쿠버네티스 클러스터가 있어 여기에 올려보았습니다. 컨텍스트를 변경하고 정보를 잘 가지고 오는지 확인해둡니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 현재 쿠버네티스 컨텍스트 확인
kubectl config get-contexts
#>
#CURRENT NAME CLUSTER AUTHINFO NAMESPACE
# docker-desktop docker-desktop docker-desktop
# kubernetes-admin@kubernetes kubernetes kubernetes-admin
#* minikube minikube minikube default
# 원격 클러스터로 변경
kubectl config use-context kubernetes-admin@kubernetes
#>
#Switched to context "kubernetes-admin@kubernetes".
# 접속상태 확인
kubectl cluster-info
#>
#Kubernetes control plane is running at https://{remote-k8s-ip}:6443
#CoreDNS is running at https://{remote-k8s-ip}:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubectl get nodes
#>
#NAME STATUS ROLES AGE VERSION
#myserver01 Ready control-plane 31d v1.29.5
#myserver02 Ready <none> 31d v1.29.5
#myserver03 Ready <none> 31d v1.29.5
cluster-info가 가져와지지 않는다면? 만약 기존 k8s cluster 인증에 특정IP 만 허용되어 있다면 다음 명령어로 갱신해 줄 필요가 있습니다. 저는 인증서 내 k8s의 private ip 만 추가되어 있어 public ip를 추가해 주었습니다.
(spark 세팅)
로컬에 spark 가 설치되었다면 따로 세팅할 부분은 없습니다. 아래는 제가 실습한 로컬PC의 버전 정보입니다.
1
2
3
#spark version: 3.5.4
#Scala version: 2.12.18
#java version: OpenJDK 11.0.25
Step 2. Spark 용 Docker 이미지 준비
Kubernetes는 Spark 애플리케이션을 실행할 때 각 실행 단계를 컨테이너로 실행합니다. 따라서 Spark 에서 실행할 Docker 이미지가 필요하며, 이를 원격 레지스트리에 푸시해야 합니다. 저는 Spark example jar 들을 포함하고 있는 공식 docker 이미지를 사용할 것이므로 추가적인 빌드는 하지 않았습니다.
Step 3. Spark 실행 리소스 설정
Kubernetes에서 Spark Job을 실행하려면 적절한 권한(Role, RoleBinding) 이 필요합니다. 하단의 yaml 파일은 spark라는 ServiceAccount 를 생성하고, 이를 Kubernetes의 ClusterRole(edit) 과 바인딩(RoleBinding) 하는 설정입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-role-binding
namespace: default
subjects:
- kind: ServiceAccount
name: spark
namespace: default
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.io
1
2
3
4
5
6
7
8
9
10
# Service account 는 바로 생성해 둡니다.
kubectl apply -f spark-serviceaccount.yaml
#>
#serviceaccount/spark created
#rolebinding.rbac.authorization.k8s.io/spark-role-binding created
# pods 생성이 가능한지도 체크해 둡니다.
kubectl auth can-i create pods --as=system:serviceaccount:default:spark -n default
#>
#yes
Step 4. spark-submit 실행
이제 준비가 다 되었으므로 spark-submit 을 통해 Job을 제출합니다. 이때 사용된 KUBECONFIG 는 여러대의 cluster 가 로컬에 등록되었을경우 해당 config 를 알맞게 적용하기 위한 것으로 각자 세팅에 맞게 사용하시면 됩니다.
1
2
3
4
5
6
7
8
9
KUBECONFIG=/Users/{username}/.kube/kubeconfig-remote-onpremise spark-submit \
--master k8s://https://210.94.87.94:6443 \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=apache/spark:3.5.4 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.namespace=default \
--class org.apache.spark.examples.SparkPi \
local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar 100
Step 5. 결과 확인
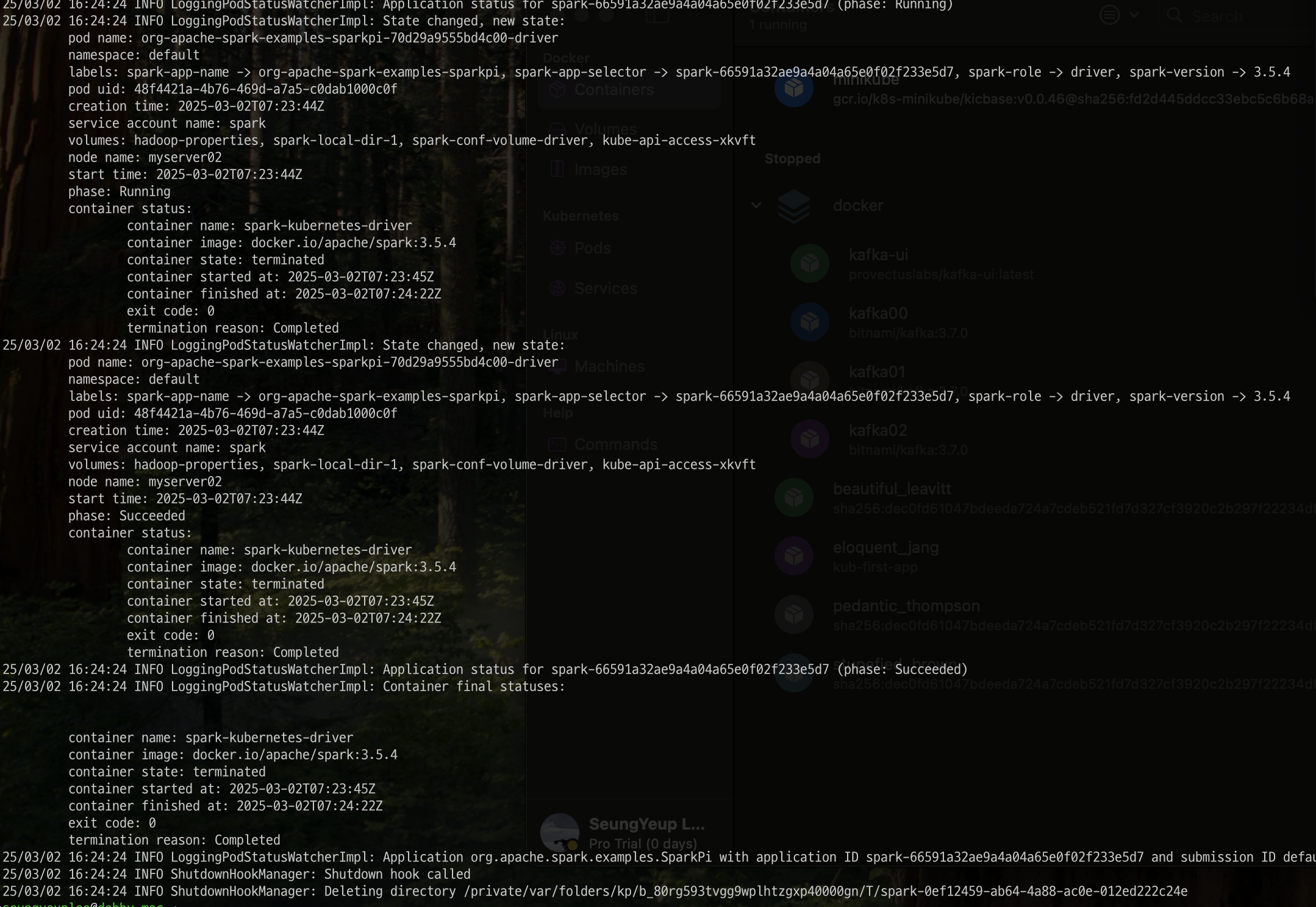
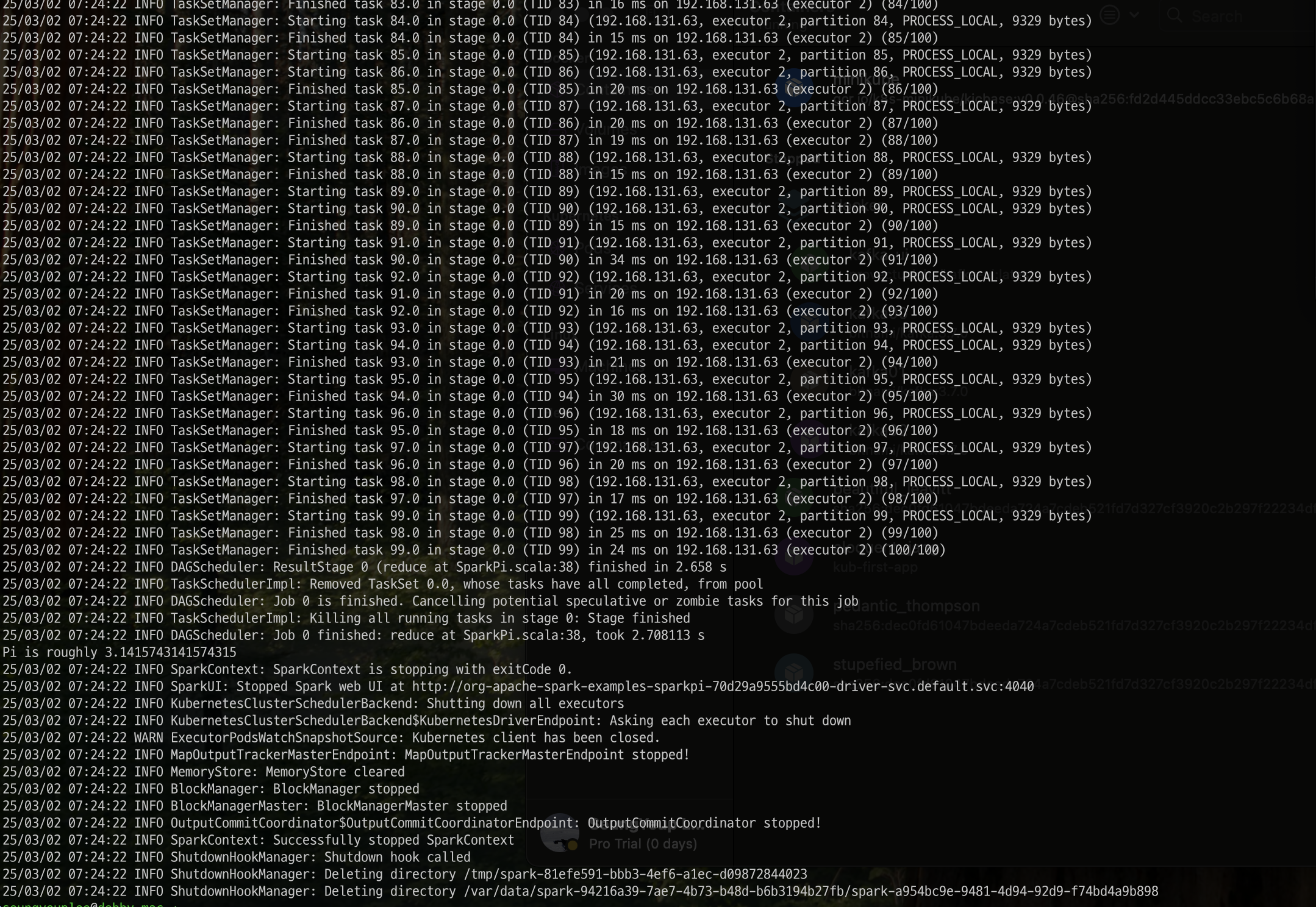
spark-submit 결과는 다음과 같이 잘 수행된 것을 확인 할 수 있었습니다. submit을 하고 나서 kubectl 명령어로 pod를 가지고 오면 아래 응답값과 캡쳐 내용처럼 어떻게 수행되었는지에 대한 log들을 확인할 수 있습니다. 정상적으로 pi 값을 계산해낸것으로 확인됩니다.
1
2
3
4
5
6
kubectl get pods
#>
#NAME READY STATUS RESTARTS AGE
#org-apache-spark-examples-sparkpi-55ca6b9555b70d29-driver 0/1 Completed 0 3m
kubectl logs -f org-apache-spark-examples-sparkpi-55ca6b9555b70d29-driver
#kubectl port-forward org-apache-spark-examples-sparkpi-55ca6b9555b70d29-driver 4040:4040 -n default
Spark Operator (Kubernetes CRD 활용) 실행
이번에는 Kubernetes에서 Spark Operator 를 활용하여 Spark Job을 실행하는 방법을 알아봅니다. Spark Operator 는 kubectl apply -f 명령어로 Spark Job을 Kubernetes 리소스로 실행할 수 있도록 해줍니다. 실행 과정을 복기하면 다음과 같습니다.
동작방식
- Spark Operator가 Kubernetes 클러스터에서 실행됨.
- 사용자는 SparkApplication이라는 Kubernetes Custom Resource Definition (CRD) 를 생성.
- Spark Operator가 SparkApplication을 감지하고, Spark Driver 및 Executor Pod를 자동으로 생성.
- Spark Job이 끝나면 Pod가 자동 정리되며, Job 상태가 Kubernetes 리소스로 관리됨.
Step 1. Spark Operator 설치 (helm)
현재는 Spark Operator 의 Helm 차트는 Kubeflow 커뮤니티에서 관리하고 있으며, 새로운 Helm 저장소 URL은 https://kubeflow.github.io/spark-operator 입니다. 따라서 해당 helm chart 를 추가해주고 kubernetes 위에 설치를 진행합니다.
1
2
3
4
5
6
7
8
9
10
# kubeflow spark-operator in helm
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
helm install spark-operator spark-operator/spark-operator --namespace spark-operator --create-namespace
kubectl get pods -n spark-operator
#>
#NAME READY STATUS RESTARTS AGE
#spark-operator-controller-7b674d78dd-lz4mm 1/1 Running 0 2m2s
#spark-operator-webhook-c88fd9895-scg82 1/1 Running 0 2m2s
Step 2. yaml 작성
Spark Operator는 SparkApplication 이라는 Kubernetes CRD(Custom Resource) 를 통해 Spark Job을 실행합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication # Kubernetes CRD(Custom Resource)
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: apache/spark:3.5.4
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar
sparkVersion: "3.5.4"
restartPolicy:
type: Never
driver:
cores: 1
memory: "512m"
serviceAccount: spark # 아까 생성한 k8s 실행 계정
executor:
cores: 1
instances: 2
memory: "512m"
Step 3. yaml 실행
준비한 yaml 파일을 실행합니다. 실행하면 yaml 에서 정의한 SparkApplication 이 생성됩니다. 이 이후에 spark-operator 가 이를 감지하고 Spark Driver 및 Executor Pod를 자동으로 생성합니다.
1
2
3
4
5
6
7
8
9
# SparkApplication 생성
kubectl apply -f spark-pi.yaml
#>
#sparkapplication.sparkoperator.k8s.io/spark-pi created
kubectl get sparkapplications
#>
#NAME STATUS ATTEMPTS START FINISH AGE
#spark-pi SUBMITTED 1 2025-03-02T09:47:04Z <no value> 7s
Step 4. 결과 확인
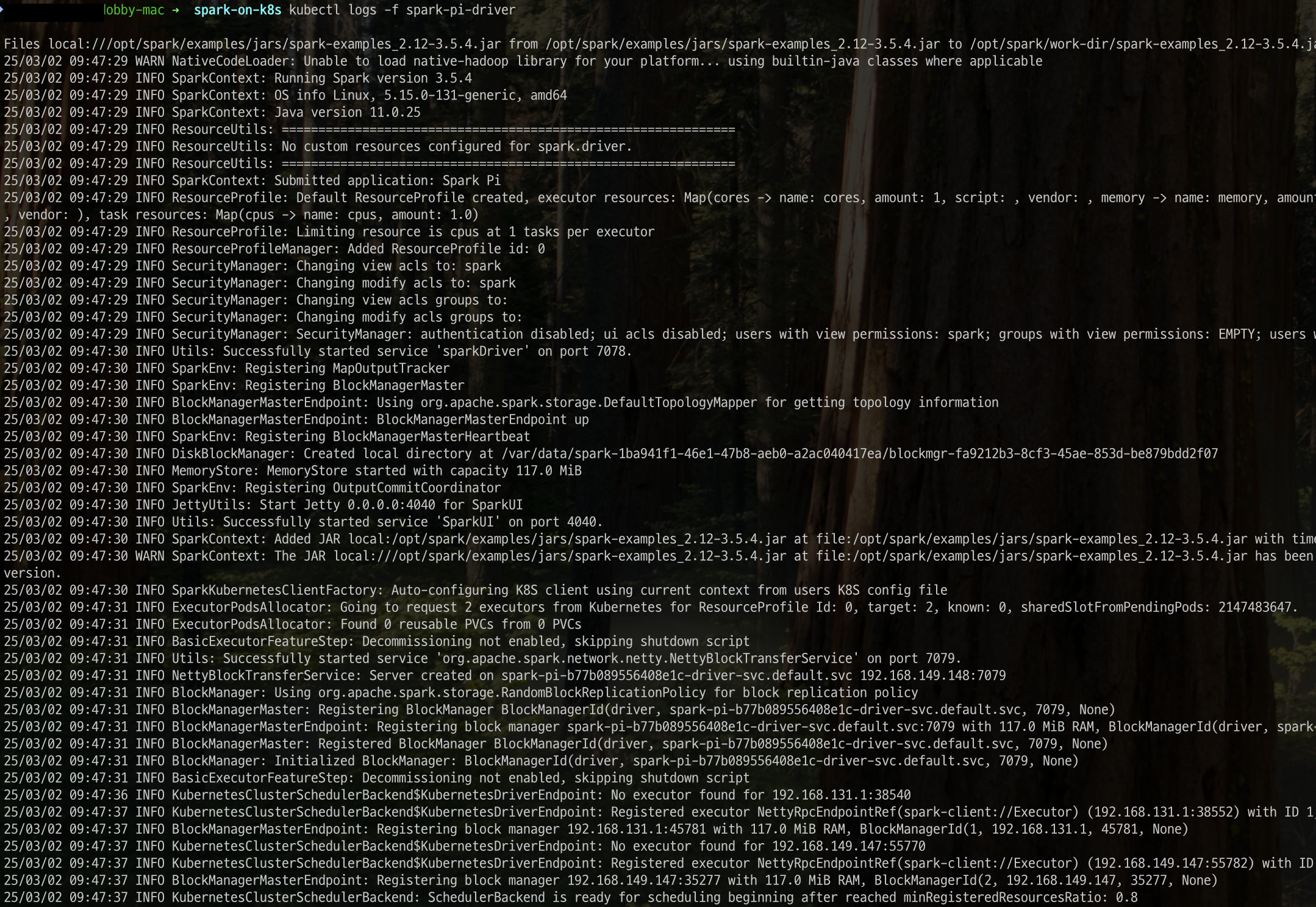
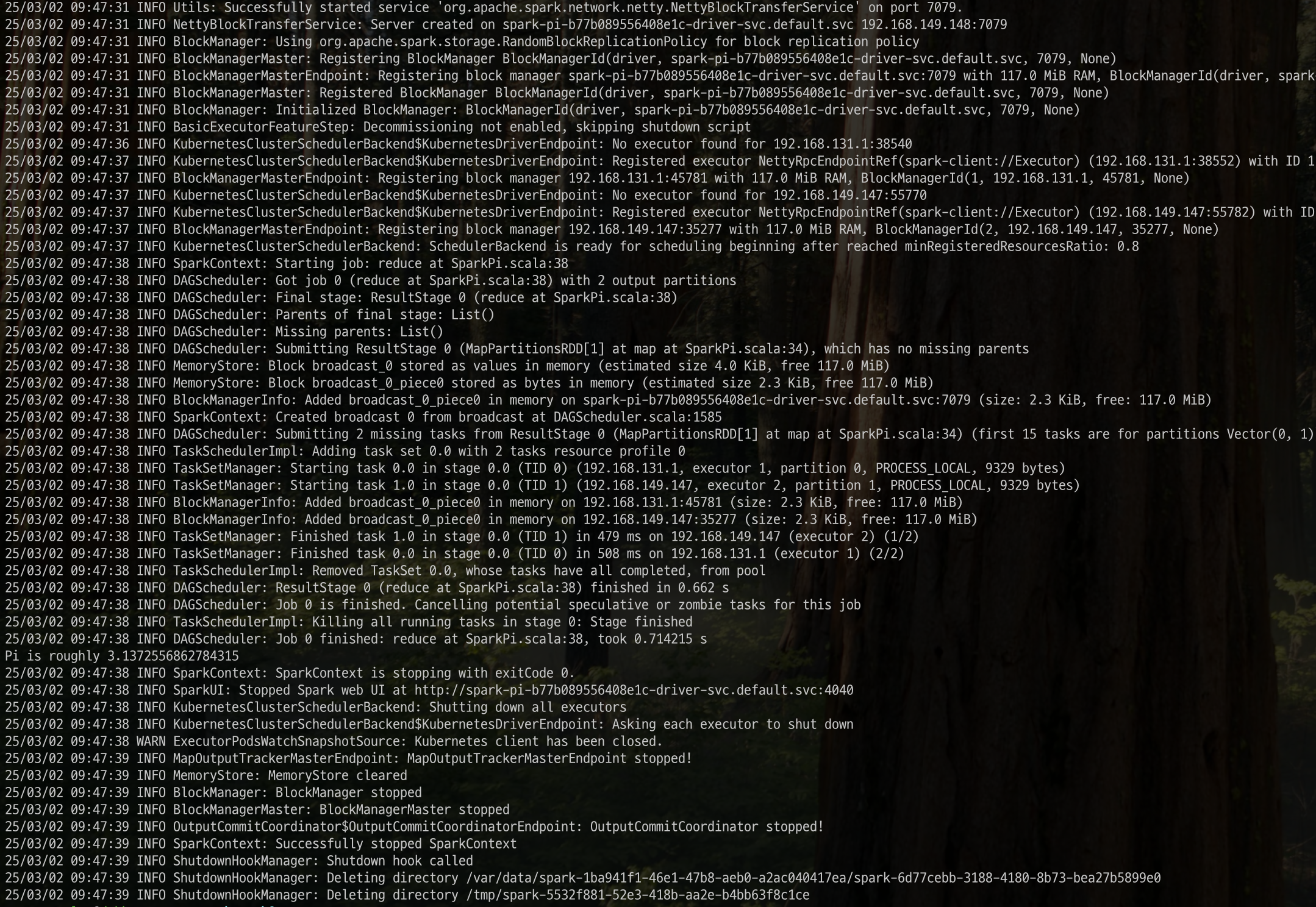
수행된 결과를 확인합니다. pod 를 열어 로그를 확인하면 pi값을 정상적으로 계산해낸 것을 알 수 있습니다.
1
2
3
kubectl get pods
kubectl logs -f spark-pi-driver
#kubectl port-forward spark-pi-driver 4040:4040
정리하며
이번 포스팅에서는 spark on kubernetes 의 주요 구성 방법인 1) Native Kubernetes Integration , 2) Spark Operator 를 각각 간단하게 테스트 해 보았습니다. 실무에서 spark on kubernetes 를 효율적으로 사용하기 위해서는 더 세세하고 많은 테스트와 공부가 필요하겠지만 대략적인 느낌을 알 수 있어 좋았습니다. 추후에도 k8s 에 리소스를 얹거나 사이드 프로젝트에 활용할 일이 생기면 종종 기록으로 남겨둬야겠습니다. 👋
참고문헌
- https://www.kubeflow.org/docs/components/spark-operator/getting-started/
- https://github.com/kubeflow/spark-operator/tree/master?tab=readme-ov-file
- https://medium.com/@SaphE/deploying-apache-spark-on-a-local-kubernetes-cluster-a-comprehensive-guide-d4a59c6b1204
- https://medium.com/empathyco/running-apache-spark-on-kubernetes-2e64c73d0bb2
- https://www.chaosgenius.io/blog/spark-on-kubernetes/